
Summary:
- Microsoft ditches Intel for Qualcomm on new Surface Copilot+ PC devices, highlighting Intel’s shortcomings in performance and efficiency.
- Intel resorts to TSMC for Copilot+ PC chips, revealing delays in Intel’s process nodes and raising doubts about regaining process leadership.
- Intel obfuscates the collapse of its Foundry business.
- Intel’s most fundamental problem is not process leadership, but competition from more efficient computing approaches.
JHVEPhoto
In June 2018, I wrote a series of articles titled “The 3 Failures of Brian Krzanich”, describing failures in mobile devices, GPU accelerated computing, and process leadership. Today, Intel (NASDAQ:INTC) CEO Pat Gelsinger faces a similar set of problems and under his leadership Intel has failed in three areas: the loss of Microsoft’s flagship Surface devices, inability to use an Intel process for its impending Copilot+ PC chips, and a silicon foundry business that has collapsed. All of these failures highlight the challenges Intel faces in regaining process leadership and fending off competition from more efficient computing architectures.
Failure #1: Microsoft ditches Intel for Qualcomm on new Surface Copilot+ PC devices
On the eve of this year’s Build developer conference on May 20, Microsoft (MSFT) quietly announced its Copilot+ PCs, including new Surface Pro tablet and Surface Laptop devices.
The new Qualcomm powered Surface devices. (Microsoft)
At the time, Microsoft disclosed that only devices running Qualcomm’s (QCOM) Snapdragon X Plus and X Elite processors would qualify as Copilot+ PCs. So even third party Copilot+ PCs would have to use Qualcomm.
Only last December, Intel launched Core Ultra laptop processors, previously known as Meteor Lake at an event dubbed “AI Everywhere”. The chips featured a new (for Intel) Neural Processing Unit (NPU) to support on device AI, and the CPU chiplets were the first to use the Intel 4 process.
Despite new CPU and GPU architectures, the combined AI performance measured in TOPS (tera AI operations per second, (10^12) ops/sec) was only 34 TOPS:
Meteor Lake AI capability. (Intel)
This was far short of the 40+ TOPS that Microsoft mandated for the NPU alone, and which Qualcomm would meet. Had Microsoft not communicated the requirement to Intel?
Most likely, Microsoft’s decision to go with Qualcomm had already been made by the time of the Meteor Lake launch in December. In terms of Microsoft’s Copilot+PC, Meteor Lake was dead on arrival.
Failure #2: Intel resorts to TSMC to make its Copilot+PC chips
Intel’s response has been to pre-announce Lunar Lake, the successor to Meteor Lake and presumably part of the Intel Core Ultra series. This time, Intel made sure to offer more NPU TOPS than Qualcomm X Elite:
Lunar Lake AI capability. (Intel)
Lunar Lake should enable PC OEMs to make Copilot+PCs using Intel, but it probably won’t allow Intel to reclaim the prestigious Surface devices. Here, the reason is performance and efficiency. In the Lunar Lake slide, Intel could only claim “Unprecedented x86 Power Efficiency”.
But there was a secret lurking within Lunar Lake, undisclosed in the Lunar Lake presentation and specifications. As was subsequently confirmed by Anandtech and others, the Lunar Lake compute chiplet is being manufactured by TSMC (TSM) on the TSMC N3 (“3 nm”) process.
So, even with the use of the most advanced process available today, Intel doesn’t expect to match the efficiency of the X Elite. And this is despite the fact that X Elite only uses the older TSMC N4 process, which is an improved 5 nm process.
But the question remains, why was Intel forced to run to TSMC in a possibly vain attempt to be competitive with Qualcomm’s X Elite? At the very least, this should raise doubts about Intel’s true progress in regaining process leadership.
Failure #3: Intel’s foundry business collapses
The reader may be shocked by this statement, given the optimistic pronouncements from the company, such as this one from February:
Intel Corp. today launched Intel Foundry as a more sustainable systems foundry business designed for the AI era and announced an expanded process roadmap designed to establish leadership into the latter part of this decade. The company also highlighted customer momentum and support from ecosystem partners – including Synopsys, Cadence, Siemens and Ansys – who outlined their readiness to accelerate Intel Foundry customers’ chip designs with tools, design flows and IP portfolios validated for Intel’s advanced packaging and Intel 18A process technologies.
Furthermore, Intel reported for its fiscal 2024 Q1 that Intel Foundry generated $4.4 billion in revenue. This could hardly be a collapse!
But Intel is engaged in some financial sleight of hand. It announced that for the new fiscal year, it has gone to an “Internal foundry operating model”. There’s nothing wrong with this, but it obscures how much revenue is being generated from external customers.
Last year, Intel reported $118 million in Foundry Services revenue for 2023 Q1. For this year, in the new reporting scheme, we can arrive at that number by subtracting the “Intersegment eliminations” of $4713 million from the reported revenue of $4831 million for 2023 Q1.
Intel 2024 Q1 segment results (Intel)
If we do the same for 2024 Q1 ($4369 million – $4353 million), the derived external revenue has come down quite a bit, to a mere $16 million.
Why has foundry external revenue collapsed? Despite all the promises for the future, the present reality is that Intel has nothing to compete with TSMC’s “3 nm” processes (N3 and variants) used by Apple (AAPL) and notably, Intel.
Back in 2021, many in the tech media had claimed that Qualcomm (QCOM) would be Intel’s first foundry service customer for its advanced Intel 20A process as in this report from Anandtech:
Per Intel’s announcement, Intel and Qualcomm are partnering up to get Qualcomm products on Intel’s 20A process, one of the company’s most advanced (and farthest-out) process node. The first of Intel’s “Ångström” process nodes, 20A is due in 2024 and will be where Intel first implements Gate-All-Around (GAA) transistors, one of the major manufacturing technology milestones on Intel’s new roadmap.
Intel 20A expectations. (Intel)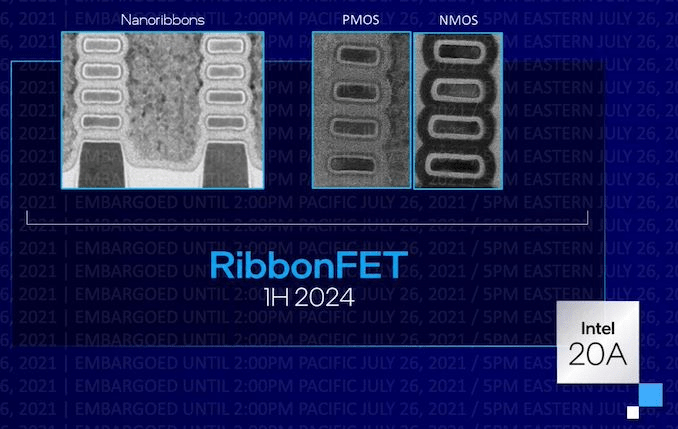
Well, here we are having just completed the first half of calendar 2024, and there’s no Intel 20A, and no Qualcomm as an Intel Foundry customer. As I pointed out at the time:
Actually, Qualcomm is neither a customer nor a partner of IFS. All Qualcomm has done is express interest in a process that Intel claims it will offer some time in the future.
There’s no legally binding commitment on Qualcomm’s part, and there couldn’t be, given that the manufacturing process doesn’t even exist yet. And Gelsinger was careful not to overclaim, saying only that he was “excited by the opportunity to partner with Qualcomm.” It’s an opportunity, not a partnership, not a done deal, not a sale.
Regaining process leadership is doubtful
At last December’s Meteor Lake launch, CEO Pat Gelsinger maintained that Intel was “on track” to complete 5 nodes in four years:
CEO Gelsinger declares “5 nodes in 4 years” on track at Meteor Lake launch. (Intel, via YouTube)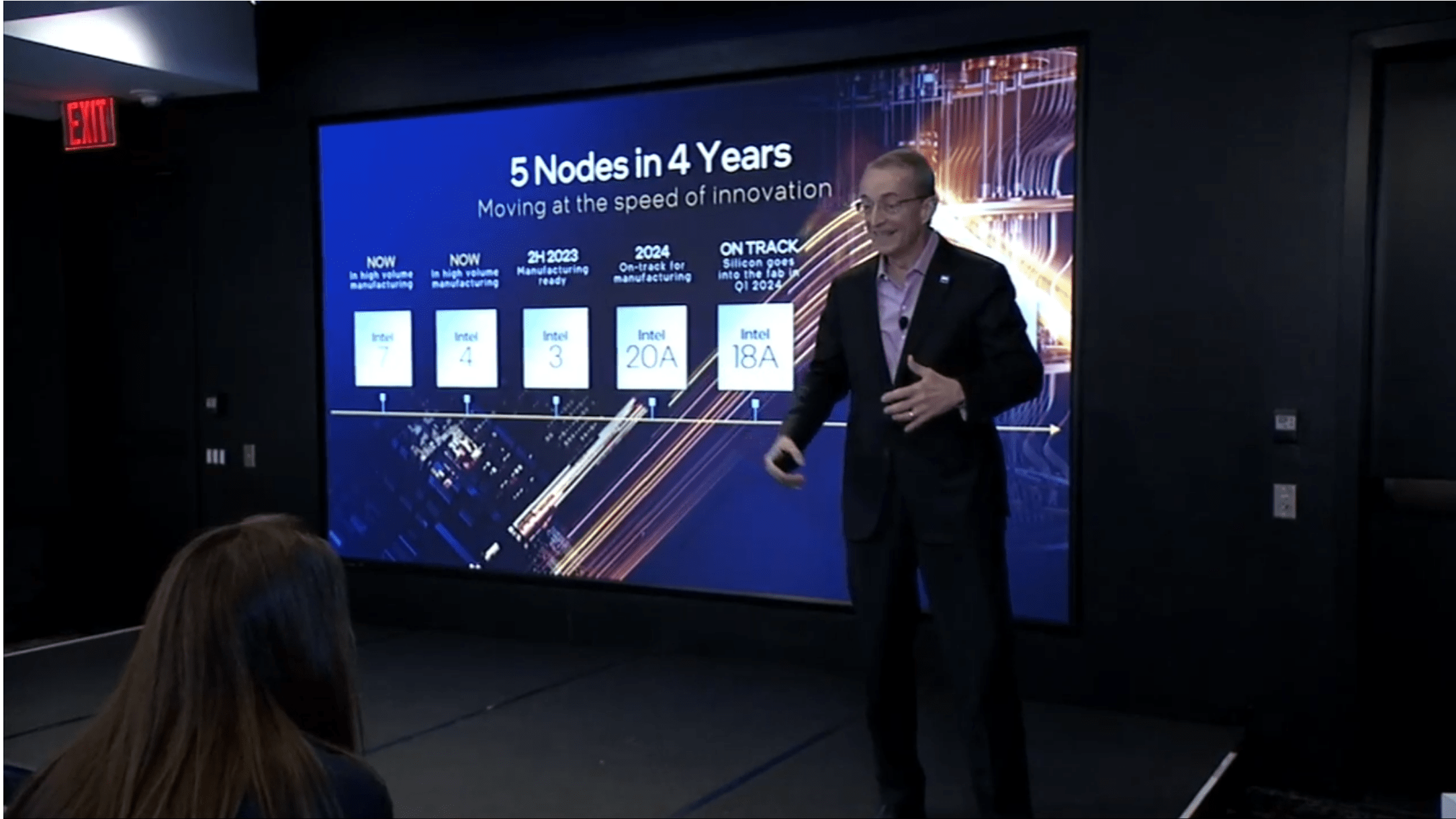
And at the Intel Foundry Direct Connect event in February of this year, Gelsinger claimed that the 5 nodes were “done”, and outlined further “progress” in advanced processes:
Intel’s latest process roadmap. (Intel)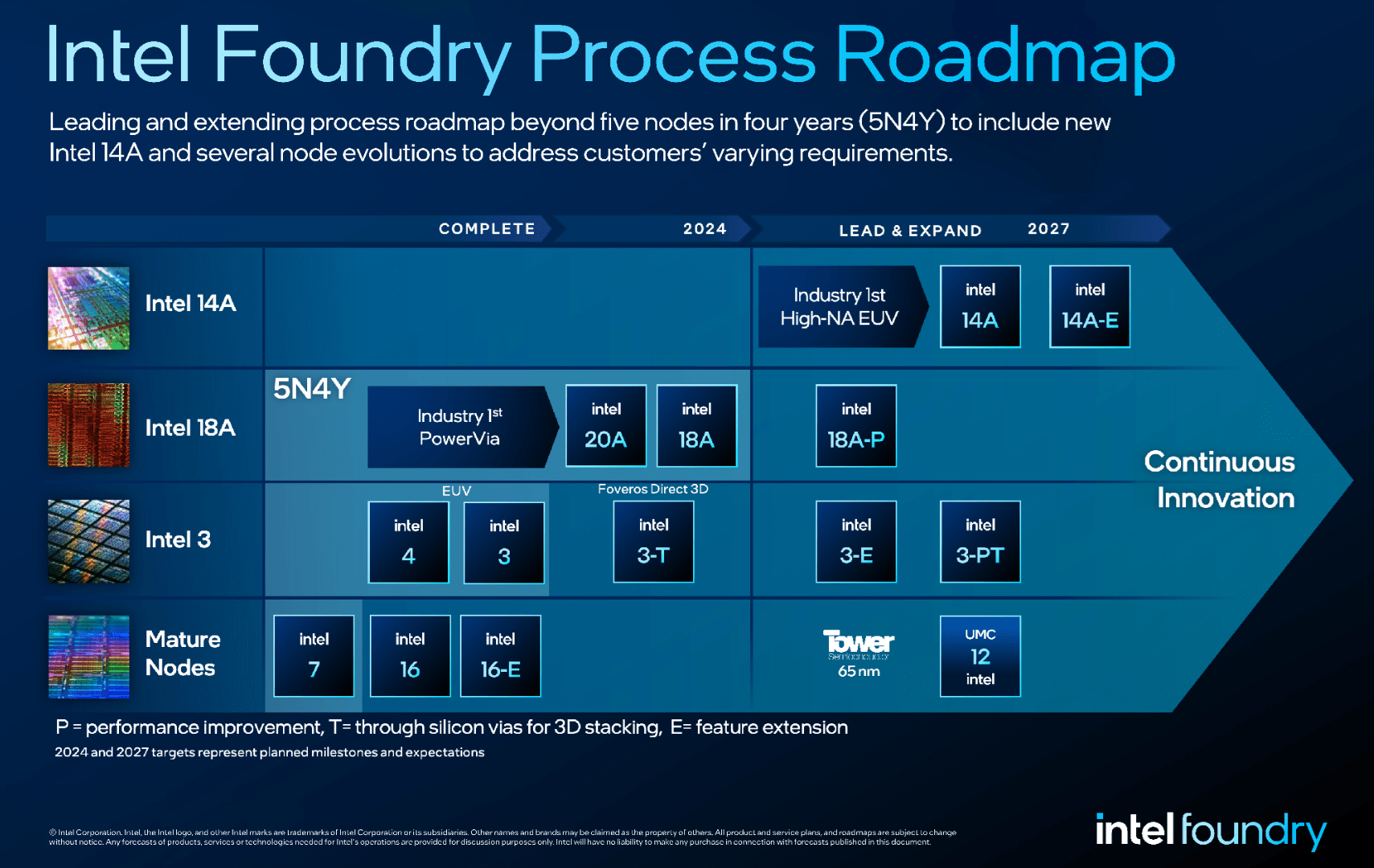
In July 2021, Intel released this chart explaining the new nomenclature of the Intel process nodes:
Intel’s process nomenclature changes in 2021. (Intel)
Note that as of the end of last year, Intel could only claim that Intel 4, its renamed 7 nm process, had achieved volume production. Intel 4 was being used for the CPU chiplets of Meteor Lake.
Based on Intel inputs, Anandtech put together this timeline for the various Intel nodes:
Intel’s process node timeline. (Anandtech)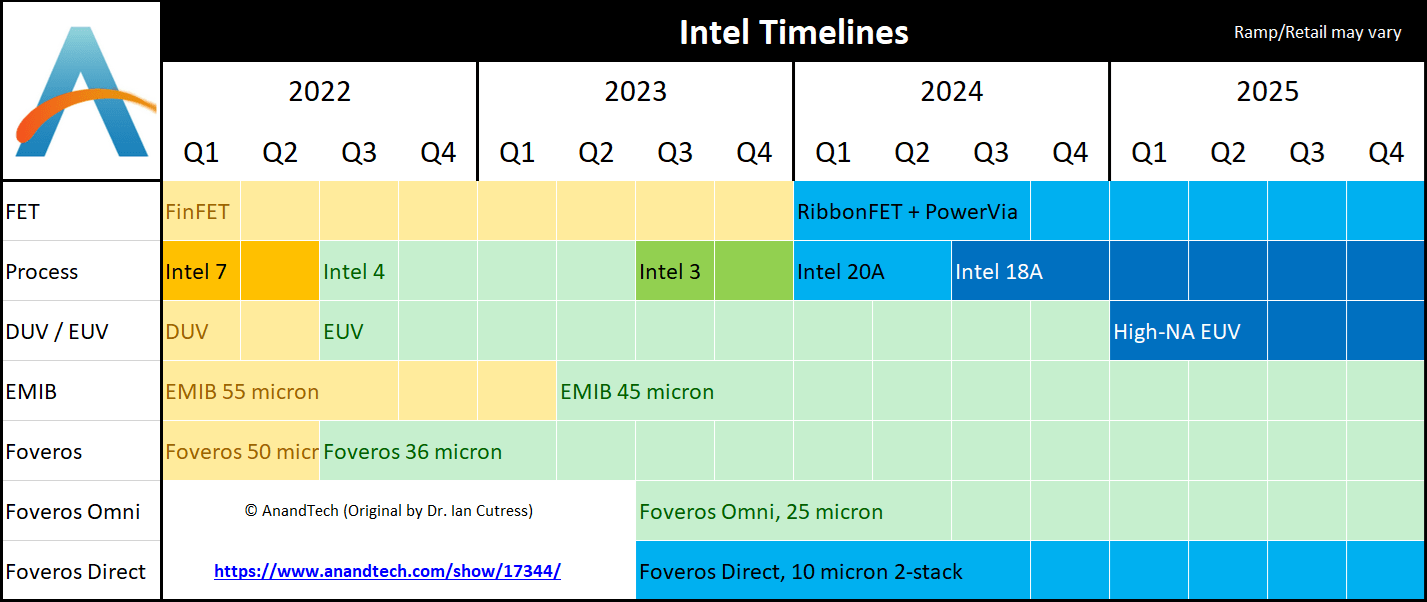
But notice that with the December launch of Meteor Lake, Intel 4 didn’t start actual production until 2023 Q4, a delay of 5 quarters. And the first products listed as Intel 3, a new range of Xeon processors dubbed “Sierra Forest”, are officially listed as launching in 2024 Q2. This implies that Intel 3 has been delayed by 3 quarters.
The launch of Lunar Lake in Q3 implies even further delays, as summarized in the chart from Anandtech:
Anandtech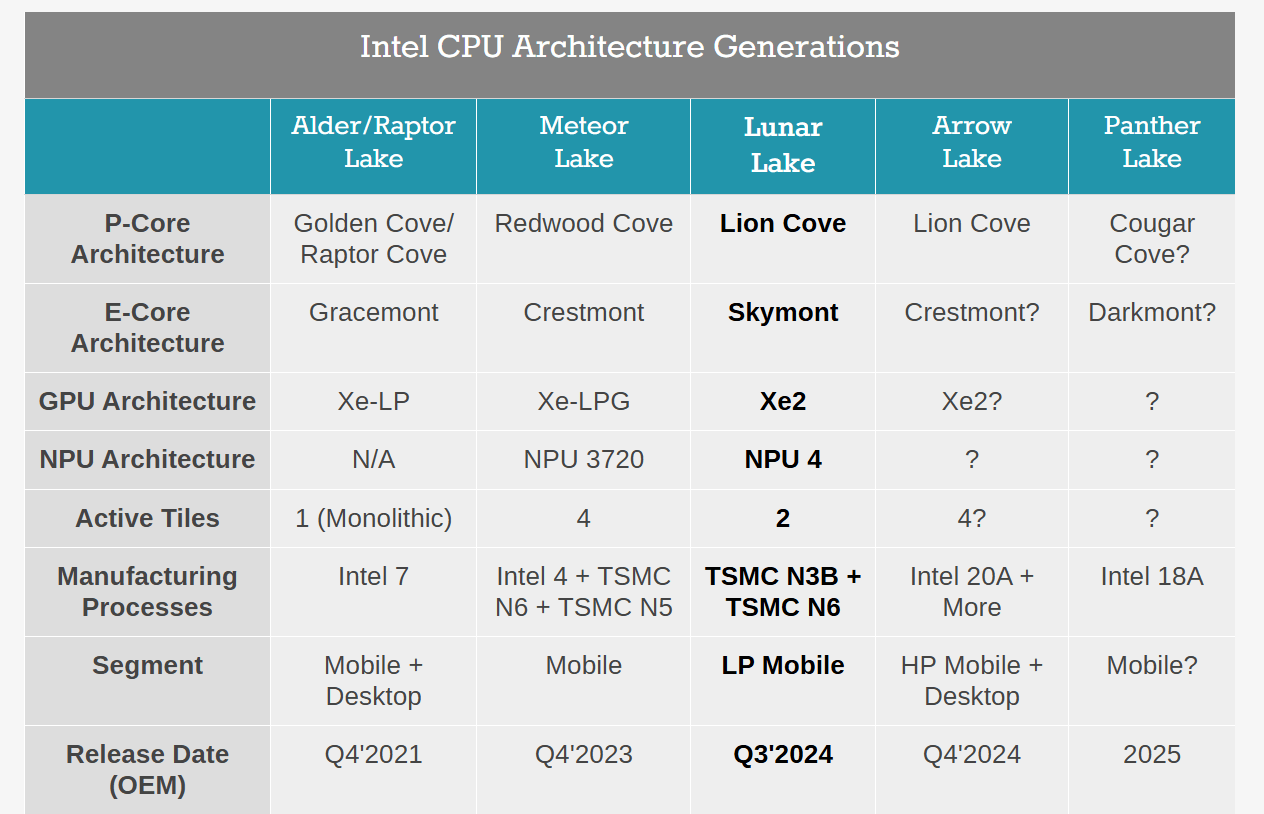
Clearly, Intel would not have needed to resort to TSMC for Lunar Lake if Intel 20A had been ready according to the timeline. How can Gelsinger claim that Intel’s process nodes are “done” when Intel 4, Intel 3, and Intel 20A are all behind schedule?
Gelsinger seems to be engaged in a self-serving redefinition of what constitutes completion of a given process node. A process node isn’t “complete” merely because Gelsinger can hold up a silicon wafer fabricated on that node in front of an audience of tech journalists.
Process nodes aren’t just about bragging rights, a marketing gimmick to convince the media of technical progress. Process nodes are about what can be manufactured in high volume, generating significant revenue and profit.
If we compare Intel’s actual production with TSMC’s actual production, the picture that emerges is very different from Intel’s claims. I’ve assembled a graphic showing representative product launch times and process nodes, up to planned launches in the current calendar quarter:
Mark Hibben
The launch dates are derived from Intel’s published data and TSMC’s customers, such as Apple, AMD (AMD), and Nvidia (NVDA). The assignments of process node class are based on published transistor feature sizes.
Intel always maintained that its 10 nm process should be considered a “7 nm” process based on feature sizes compared to TSMC, and thus the renaming of 10 nm to Intel 7 was reasonable. However, Intel 4 and 3 are most comparable to TSMC’s N5, based on published feature sizes, as shown in this chart from an Intel presentation at the 2024 IEEE VLSI Symposium:
Intel, via SemiWiki
Scotten Jones summarized the data from the VLSI Symposium presentation in the table below:
Intel, via SemiWiki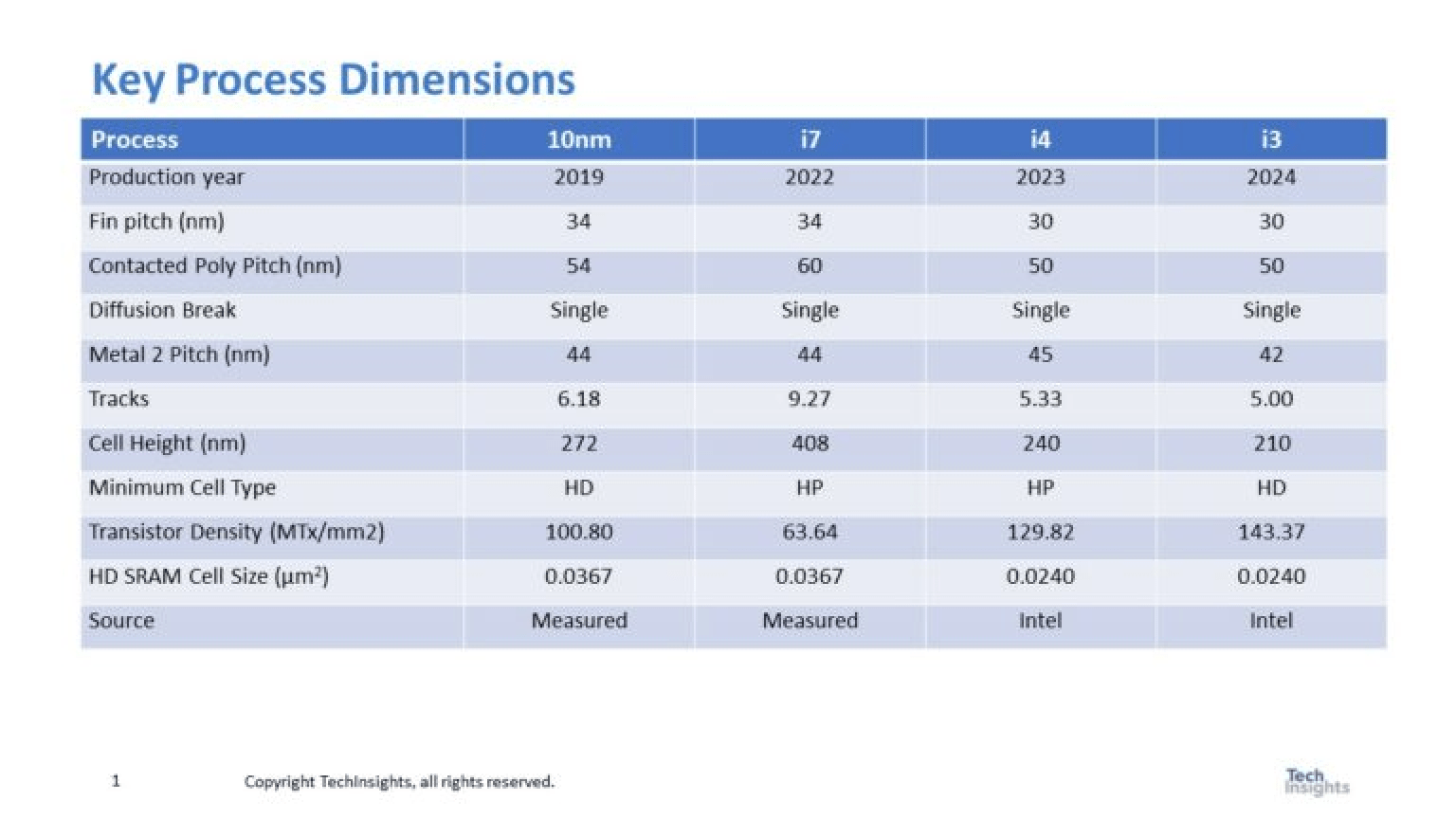
For comparison purposes, the critical parameters are the contacted poly pitch, the Metal 2 Pitch, and the Transistor Density. These are comparable to TSMC’s 5 nm process, based on data published back in 2020:
Scotten Jones, SemiWiki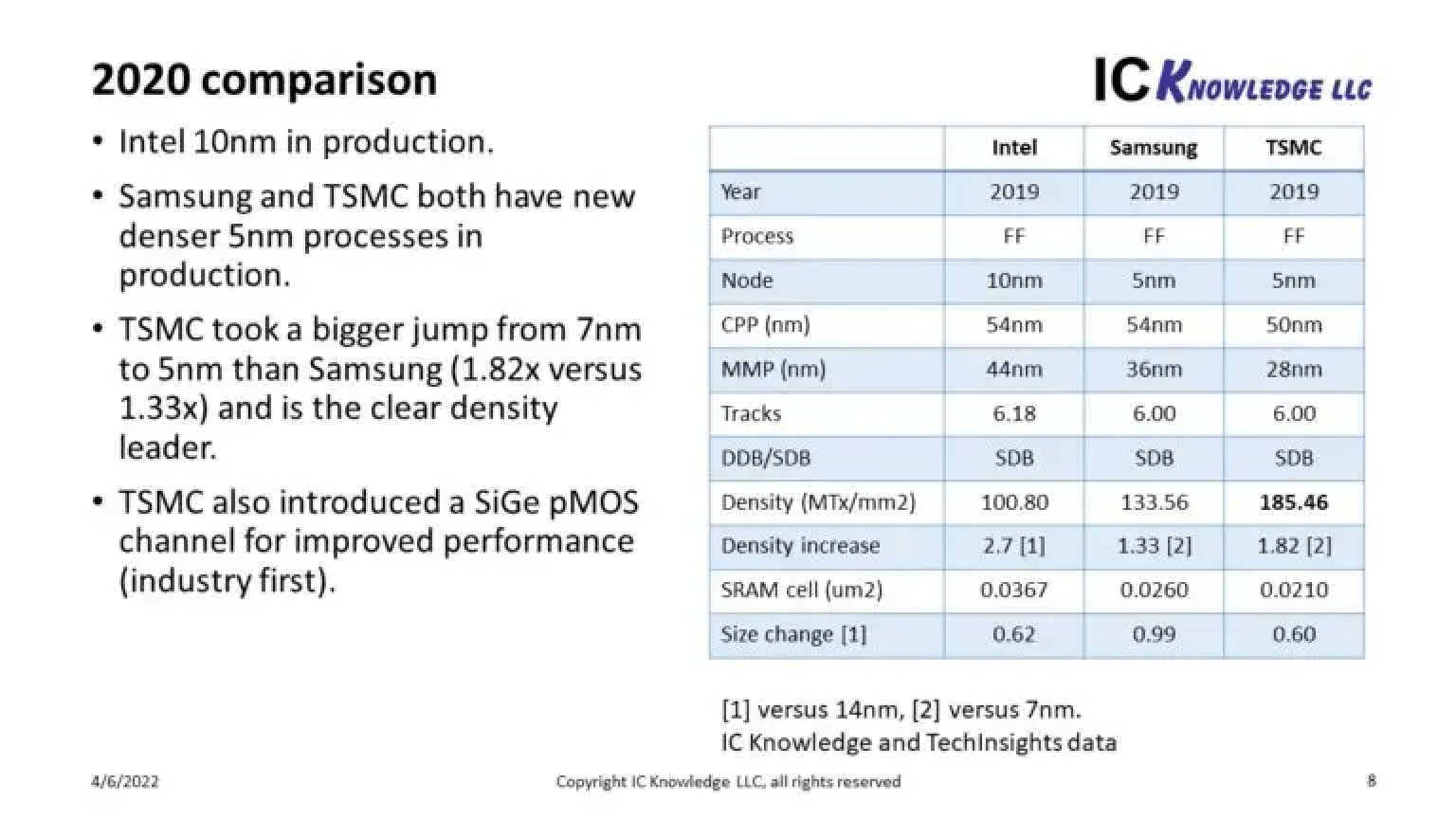
Here, the MMP is equivalent to the Metal 2 Pitch listed in the previous chart. Note also that TSMC’s transistor density for 5 nm is considerably higher than either Intel 4 or Intel 3.
Intel 3 has been referred to in the media as a “3 nm class” process, but based on Intel’s own published data, it really isn’t. It’s just a slightly improved Intel 4 process, where the focus was mostly on improving yields and the size of chips that could be produced.
When you look at what’s actually being produced, Intel is still at least a full node behind TSMC at present. And this explains the decision to use TSMC N3 for Lunar Lake, as well as Qualcomm’s apparent loss of interest in Intel Foundry.
There’s also the question of node maturity. Nodes go through a process of maturation in which yields steadily increase, prices come down, and the size of chips that can be economically manufactured increases.
In its haste to claim “5 nodes in 4 years”, Intel seems to be skipping over the normal maturation process that would occur in the Moore’s Law cadence. Intel 3 represents a maturation of the Intel 4 process, in terms of the size of the chips being produced.
But Sierra Forest Chips are enormously expensive, with the Intel Xeon 6780E processor having a list price of $11,350. Intel 3 isn’t being used to make any consumer desktop chips, which are all stuck back on Intel 7.
Meanwhile, TSMC is using N3 to make consumer chips, both for Apple smartphones and personal computers. In terms of node maturity, the gap between Intel and TSMC is more like 2 nodes.
Based on my timeline chart above, not much real progress, if any, has been made. At the end of 2021, Intel was a full node behind TSMC. Midway through 2024, Intel is at least a full node behind, and possibly more, based on node maturity.
In its quest to regain process leadership, Intel is chasing a moving target. If Intel gets Intel 20A/18A in production next year, it will have nominally fulfilled the goal of 5 nodes in 4 years, but I doubt it will recover process leadership. Intel 20A/18A is expected to have feature sizes and transistor density comparable to TSMC’s N3.
In 2025, TSMC plans to advance to its next process node, N2. TSMC has not released data for N2, but it will likely feature significant circuit shrink and transistor density increases equivalent to previous nodes. By the end of 2025, Intel will likely be about as far behind TSMC as it was when it started its “5 nodes in 4 years” crusade.
Investor takeaways: Dissembling and obfuscation reminiscent of the Krzanich era
I brought up my articles on Brian Krzanich because so much of what’s going on now at Intel reminds me of his time as CEO. Instead of real progress, we have exaggerated claims. Where there is outright financial failure, it is concealed behind reorganization.
Is this a corporate culture thing? The tendency to dissemble and obfuscate exhibited by both Krzanich and Gelsinger seems more than coincidental. Intel’s approach to its problems seems more about keeping investors sold on the company than dealing with them constructively.
And the big problem with Intel is not so much that the “5 nodes in 4 years” claim is bogus, although I think it is, but that it doesn’t even address Intel’s core problem. Intel has wound up on the wrong side of the major historical trend in computing towards more energy-efficient computing approaches.
In defending its x86 franchise, Intel has resisted more efficient computing architectures, such as GPU accelerators and ARM architecture CPUs. Intel has steadily lost ground, first in mobile devices under Krzanich, and now in mainstream personal computing and in the data center, which has been disrupted by Nvidia accelerated computing.
In the history of computing, from the earliest days of mechanical computing machines, efficiency has always won. The fixation on process leadership merely obscures Intel’s more fundamental disadvantage in x86 efficiency.
As an investor, there’s no doubt in my mind that Intel is a Sell. And U.S. policymakers should be concerned about where Intel is going. For better or worse, Intel is the best hope of the U.S. for regaining independence and sovereignty in advanced semiconductor manufacturing.
I have urged this before and will continue to do so: Intel should spin off Intel Foundry and make it truly independent. Then Intel Products can go ahead and prop up x86, only to eventually wither and die, and Foundry can become the true industry leader this country needs it to be.
Analyst’s Disclosure: I/we have a beneficial long position in the shares of TSM, AAPL, NVDA, MSFT either through stock ownership, options, or other derivatives. I wrote this article myself, and it expresses my own opinions. I am not receiving compensation for it (other than from Seeking Alpha). I have no business relationship with any company whose stock is mentioned in this article.
,
Seeking Alpha’s Disclosure: Past performance is no guarantee of future results. No recommendation or advice is being given as to whether any investment is suitable for a particular investor. Any views or opinions expressed above may not reflect those of Seeking Alpha as a whole. Seeking Alpha is not a licensed securities dealer, broker or US investment adviser or investment bank. Our analysts are third party authors that include both professional investors and individual investors who may not be licensed or certified by any institute or regulatory body.
Consider joining Rethink Technology for in depth coverage of technology companies such as Apple.