
Summary:
- There has been a cost explosion in AI caused by spiraling model size and Nvidia’s data center GPUs.
- Bucking the trend, and violating the old laws of model scaling, Google released “significantly smaller” language models that seem to perform very well, and much better than their larger predecessor.
- The opportunity here is to offer performant language model APIs at significantly lower server-side costs compared to what OpenAI is offering and make free open source alternatives look less attractive.
- Running this at scale on TPU v4 also highlights the cost benefits versus NVIDIA hardware to AI cloud customers.
- While Google has had a lot of problems in the past turning good technology into profitable products, this all adds up to a coherent AI strategy, which they have never had.
Annual Google I/O Event Held In Mountain View, California Justin Sullivan
Standing It On Its Head
At Long View Capital, we have themed portfolios built around technological and regulatory trends. Of course the one for AI is seeing the most rapid pace of change lately. I did a ground-up rewrite of the portfolio and accompanying explainer article in February based off the trends that were evident then in the wake of ChatGPT, and it may already be obsolete in the wake of 2023 Google I/O (NASDAQ:GOOG). Things are moving at a breakneck pace.
The thesis behind the current portfolio:
- ChatGPT signaled a leap in model size and capabilities.
- But with that came an even bigger leap in cost structure. Costs scale exponentially with model size.
- GPT-4 was an even bigger leap in model size and costs. Everyone is chasing that. Bigger is better.
- There is a gold rush atmosphere.
- What that adds up to is picks-and-shovels plays, favoring large deep-pocketed incumbents plus their investment partners in hardware, cloud infrastructure, and foundational model APIs.
If what Google announced pans out and can be productized, it drastically changes much of those first three bullets.
Exploding Costs
There was a rule in AI training, just violated by Google, that for optimal performance, AI model size had to rise exponentially with the size of the data corpus being trained. This caused language models to balloon in size. For example, at OpenAI:
- GPT-1 (2018): up to 117 million parameters
- GPT-2 (2019): up to 1.5 billion parameters
- GPT-3 (2020, the first model post-Microsoft $1 billion investment): up to 175 billion parameters.
- GPT-4 (2023): OpenAI isn’t saying, but probably pushing a trillion or more.
We can really see how this has led to a cost explosion in the difference between the rates OpenAI is charging for the GPT-3.5 application programming interface [API] and the GPT-4 API. Take this exchange I had with New Bing in Creative mode:
Prompt: Please write a poem about Google’s new PaLM 2 models with the theme that they are small but powerful. You may choose any rhyming pattern you like, but please make it rhyme, and keep the rhyming pattern consistent.
I will spare you Bing’s verse, but it responded with 1-sentence intro, and a 12-line poem, more or less what I asked for. But that silly exchange is pretty expensive when you scale up. Here’s what Microsoft (MSFT) would be paying OpenAI for that, were they paying the full API rate, which they are not.
GPT token calculator. OpenAI API pricing.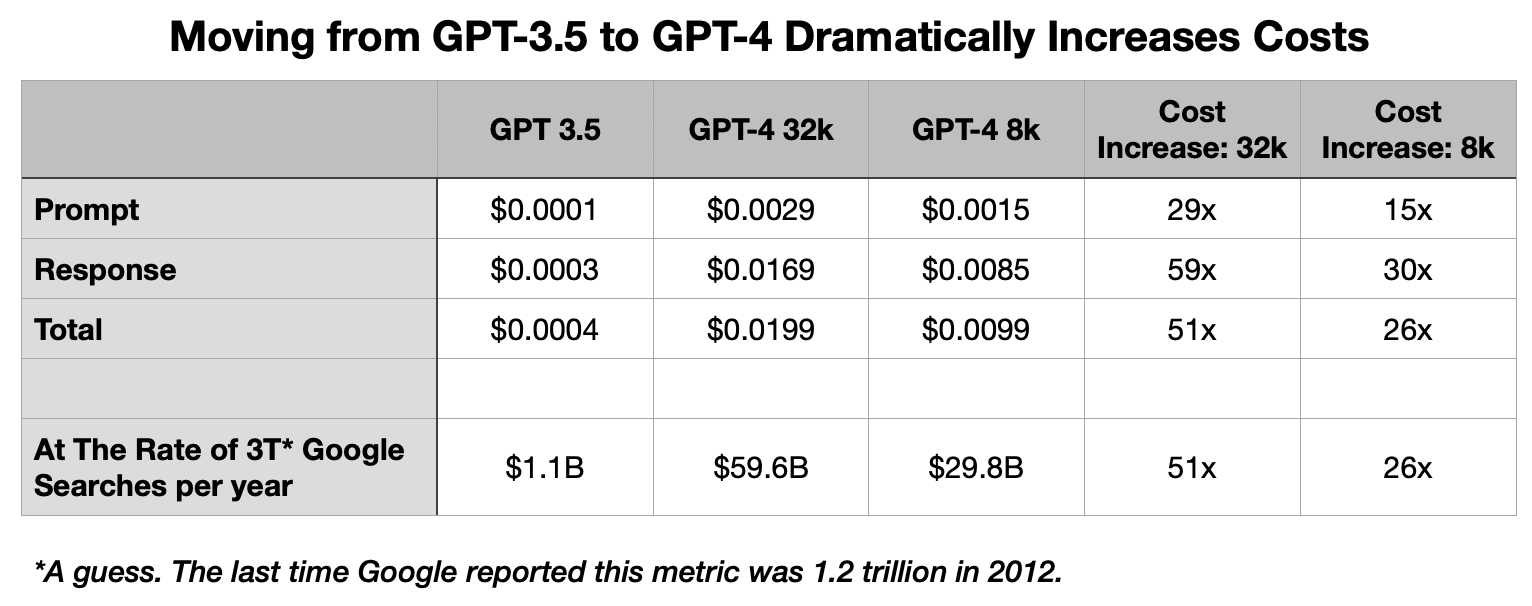
There are two flavors of GPT-4, one half the price of the other, but even the cheaper API gives you a cost increase of 2,563% over GPT-3.5 for this exchange. To scale a product based on GPT-4 up to Google Search levels implies astronomical costs.
We see this cost explosion in the startup world, beginning with OpenAI. OpenAI began as a non-profit, but lost the trust of their main sugar daddy, Elon Musk, who wound up reneging on 90% of a pledged billion-dollar donation in 2018. To fill the void, OpenAI became a “capped profit” company, whatever that means, which opened up the door to a Microsoft investment of $1 billion in 2019. They burned through that building DALL-E, GPT-3, and GPT-4.
In the wake of ChatGPT’s release, they secured another $10 billion over several years from Microsoft. Like the first deal, much of that comes in the form of Azure’s Nvidia GPU cloud infrastructure, on which all this runs. They just closed another funding round of $300 million to allow employees to exit some of their shares and raise more cash.
The Information reported last week that in 2022, OpenAI lost $540 million. Since they likely had substantially no revenue in 2022, that’s a good window into their cost structure before the GPT APIs went live, bringing in revenue, but also jacking up those costs.
They also reported that CEO Sam Altman has been telling people privately that he thinks they will have to raise $100 billion altogether. Before profits.
When asked if GPT-5 was under development any time soon, Altman scoffed at the idea. Who could afford such a thing?
Anthropic, a startup from former OpenAI employees, is looking to raise $5 billion over the next two years. Their next model will cost $1 billion over 18 months, so it looks to me like they are the ones who think they can afford such a thing.
What’s causing this is the explosion in model size, and Nvidia’s data center GPUs, the A100 and new H100 (H100 production is still ramping, so the A100 remains dominant for now). If you want to train a model on the scale of GPT-3 and run it in production at scale, 10k of those GPUs is a good starter kit. That will run $100 million, if you can get that many. And that’s before any other data center hardware — CPUs, memory, storage, network — and you will need a lot of that stuff too.
There are also substantial costs to run that many GPUs. 10k H100 GPUs running 24/7 would use 31 gigawatt-hours a year, about the same consumption as 2,800 average US homes. Assuming the data center is located in a very low power cost region ($0.07 a kilowatt-hour), that’s still over $2 million a year, just to power the GPUs.
Triple or quadruple all this if you want to do something on the scale of GPT-4.
We are seeing it in publicly traded companies as well. C3.ai (AI) looks like a huge beneficiary of this gold rush on paper. They sell tools for companies to create models and predictions around their own data. But, their costs are out of control:
C3 quarterly earnings releases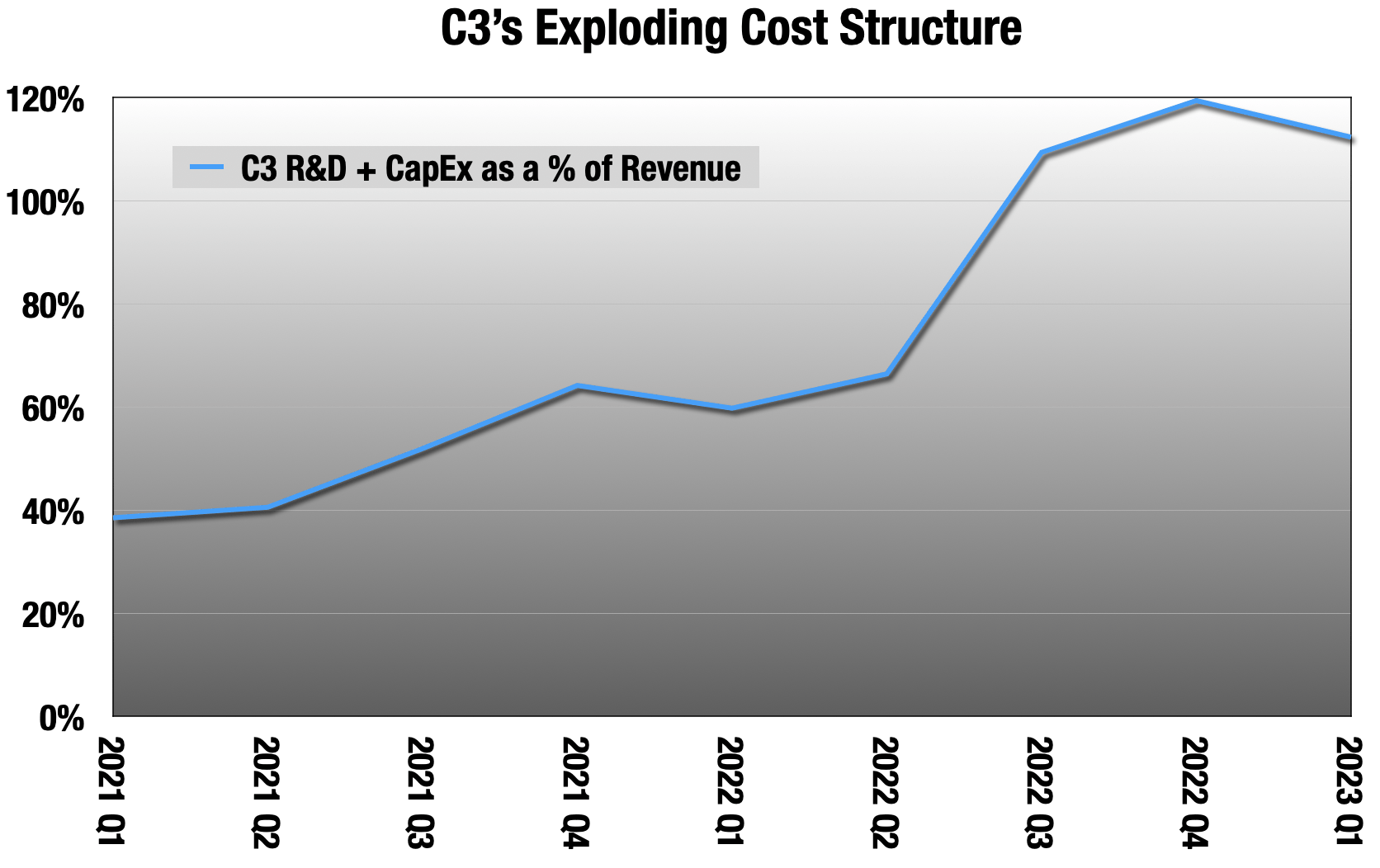
For the last 3 quarters, over 100% of revenue is going to R&D or Capex. Even Microsoft is seeing their cloud margins shaved by this new cost structure.
Microsoft quarterly earnings releases.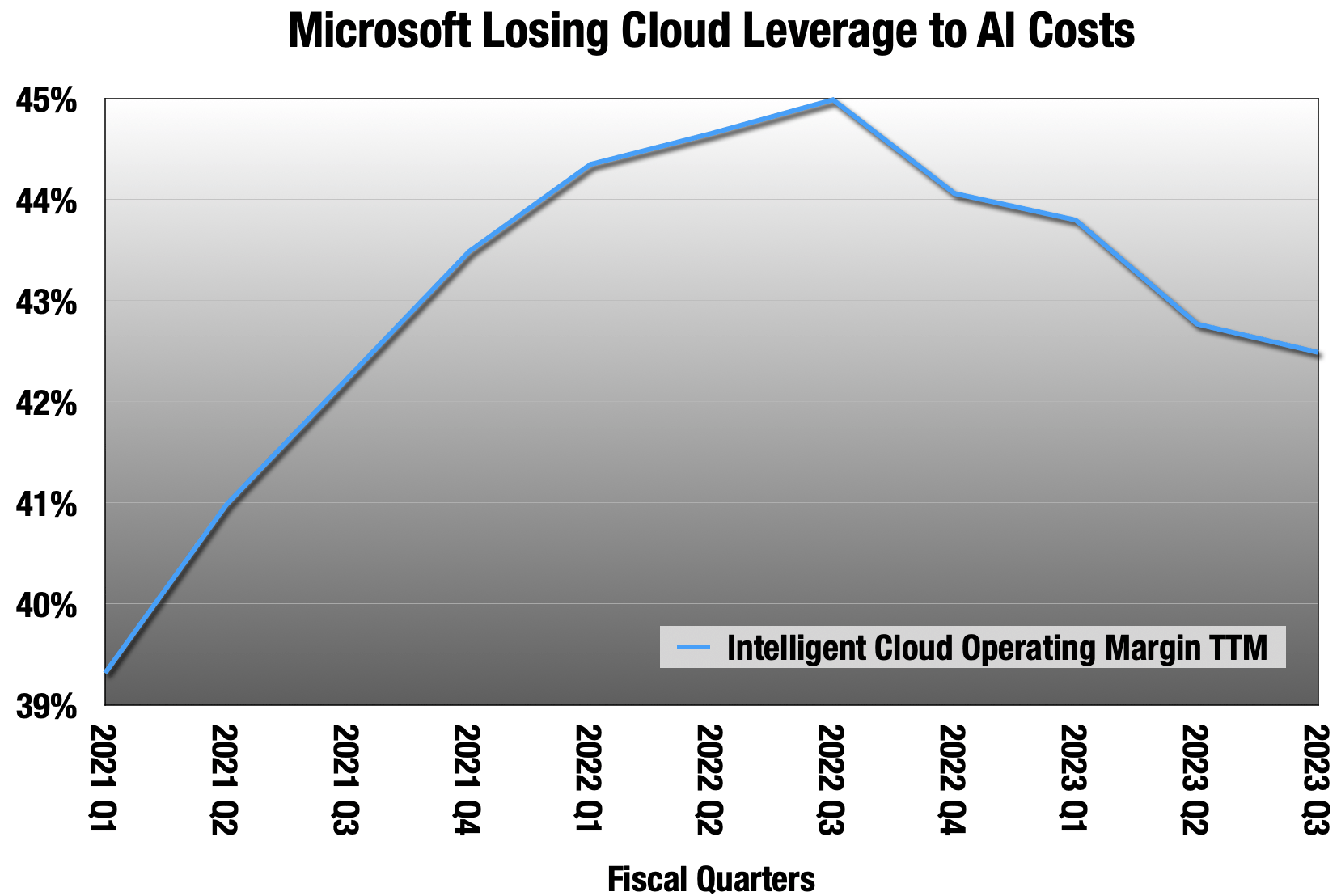
I don’t know that I have ever seen anything as ripe for disruption as Nvidia’s AI hardware dominance. They are taking margin from everyone in AI, including giant companies like Microsoft. This doesn’t mean they will be disrupted any time soon, but the incentives are there. If it does happen, I don’t think it will be a competing GPU from AMD (AMD) or a Chinese company, but another type of hardware, or even software, like small-but-powerful language models.
Google already had a hardware weapon in this battle to lower costs, their Tensor Processing Units, or TPUs. We’ll talk about those in a moment, but they announced their second weapon last week.
PaLM 2
The important thing that happened at Google I/O was not a foldable phone, but Google declaring that they were standing what I wrote in the introduction all on its head. Instead of announcing a new language model bigger than their PaLM model as was expected, they announced a much smaller one, PaLM 2.
- LaMDA (2021): up to 137 billion parameters.
- PaLM (2022): up to 540 billion parameters.
- PaLM 2 (2023): they are not saying exactly, but “significantly smaller” than PaLM.
Google would like to change the focus from model size metrics to performance metrics.
The smallest of the 4 versions of PaLM 2 can run quickly on a phone or a PC without an internet connection. The largest model will show a drastic reduction in server costs to run at scale. It will be a fraction of the costs of GPT-4 or PaLM.
But how does PaLM 2 perform? In an accompanying paper, Google showed that PaLM 2 outperforms the much larger PaLM significantly, and can also do a lot that PaLM can’t, like be multilingual, and coding. They only compared it to GPT-4 in one section of tests, the “Reasoning” tests, like Winograd pairs. Here, it did very well compared to models that are much larger.
Higher is better (Google PaLM 2 paper)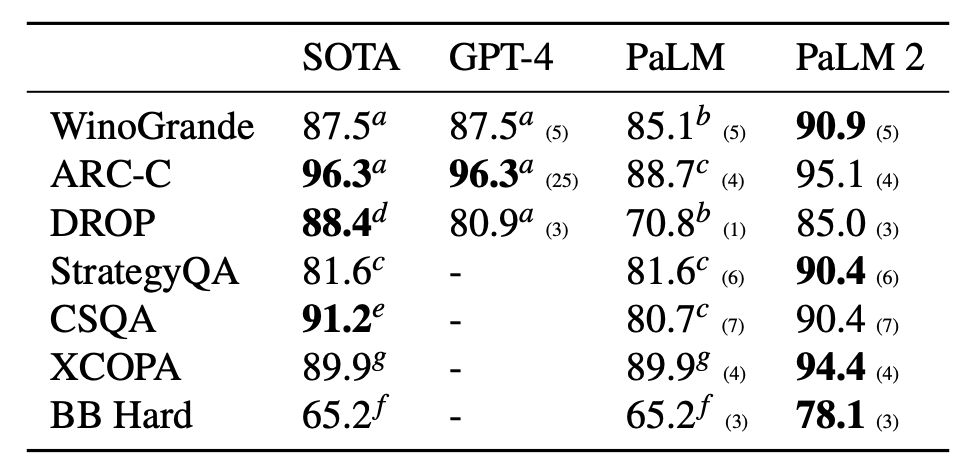
I will assume that it did not perform as well as GPT-4 in other tests, or otherwise they would have certainly shown those comparisons rather than just the PaLM comparisons.
How did they do this? In the paper, Google expends a lot of words on a new law of model scaling. What they show:
- There is an ideal model size for a given compute budget.
- Rather than scaling exponentially with the size of the training data, the ideal model should scale 1:1 with training data.
The conclusion is that if you start with a compute budget, that tells you what your ideal model size is, and how much data you need to train it. Compared to the old exponential law, the training data corpus is much larger, and the model is much smaller.
But beyond that, Google gives us very little detail into how they made PaLM 2. We don’t really know how they kept it so slim, nor did we get any detail on the training corpus. Like OpenAI, Google has become much less forthcoming with AI research details than they had been.
The tests in the paper are ones developed by AI scientists as benchmarks, but that doesn’t always translate into real world performance. My initial experiences with the new model in Bard are promising; it is certainly better than what came before, which actually I liked more than most people. One thing is for sure: my conversations with Bard just got a lot cheaper to Google.
But if this all pans out, it is a cost structure revolution for language models.
Another way Google is saving money is cutting out Nvidia altogether by training and running PaLM 2 on their own hardware, the TPU.
TPU
Elon Musk and Microsoft may have been OpenAI’s sugar daddies, but Google was everyone else’s sugar daddy for over a decade of AI research. Google has worked on AI longer and harder than anyone else, and it was already used throughout their consumer products, even before the integration of language models. They made their own smartphone chip, just so they could add more AI features to Pixel, and differentiate it in a crowded Android world.
About a decade ago, Google hit a wall with the hardware that was available to them, including from Nvidia. What emerged from this was the first “AI accelerator,” TPU version 1, in 2015. That was for internal use only, but versions 2 through 4 are available for rent on Google Cloud at significant cost savings versus Nvidia setups.
AMD/Xilinx, QUALCOMM (QCOM) and Intel (INTC) also have AI accelerators. AWS has their own, also hosting Intel’s, and Microsoft is also reportedly working on one for Azure, maybe with AMD assisting.
This economy does not come without a cost. What makes AI so computationally expensive is all the floating point matrix math at the core of machine learning that GPUs can be tuned to specialize in. AI accelerators like TPU do a workaround that is much less computationally expensive, but you wind up losing precision in the process compared to GPUs. But a lot of research shows that outside of scientific applications like drug discovery, those high levels of precision from GPUs are not needed for most AI tasks.
A great product to show off TPU v4’s performance and cost saving is a language model that is small-but-powerful, and that runs on the hardware at scale, like PaLM 2.
Google’s Product Problem
This brings us to the elephant in the room, which is Google’s longtime problem in developing profitable products internally. Since 2006, Google has launched and killed 281 products, with 4 more on the chopping block this year. Their problem had been focus. They threw lots of beta software out into the world hoping something would stick. But because they kept doing that, nothing got the focus it needed to become a product that made a profit. They added YouTube, the ad network, and Android as acquisitions, but Search remains the only major profit center that was internally developed from the beginning.
But the AI challenge from Microsoft/OpenAI has maybe turned Google into a more focused company, one that can turn this into a profitable product at the kind of scale that makes a dent in their operating statement. To be clear what I am talking about:
- A language model API that is competitive in performance with GPT-3.5 or even GPT-4. Integrated into Google products, also to show off capabilities.
- But that also has far cheaper server-side expense. This would allow them to undercut OpenAI on pricing while maintaining margin and make less performant but free open source alternatives look less attractive.
- Run that all at scale on TPU v4 to highlight the cost advantages to cloud customers.
- Also, license the smallest version to be installed along with apps on phones and PCs to run locally, off network.
This adds up to a coherent AI strategy, something Google has never had. But in the end, it will depend on whether these models are really as good as they say they are, and how well they execute. Both of those are up in the air.
Other Risks to Google
I was a longtime Google shareholder until April 2022. I sold on general macro concerns along with a lot of other stocks, but I also think Google faces three very big risks that concern me more now than they did a year ago.
The first is that I think they have let Search go downhill. There are too many ads in the first page of results, often pushing the actual search results off the initial view. Many types of common searches are now dominated by low-quality SEO results. I no longer use it much, and a lot of the people I know in the tech world are in the same boat. Like Nvidia’s data center GPUs, Search is also ripe for disruption. Like Nvidia’s data center GPUs, that doesn’t mean it will happen any time soon. Unlike Nvidia the problem is not costs, but that they have let the product get worse. Search was 57% of Google revenue in 2022.
The second is that, even though they are trying to squeeze every last ad dollar out of every bit of ad real estate at Search and YouTube, I believe the high-growth period of the digital ad business is coming to an end.
Google and Facebook quarterly results.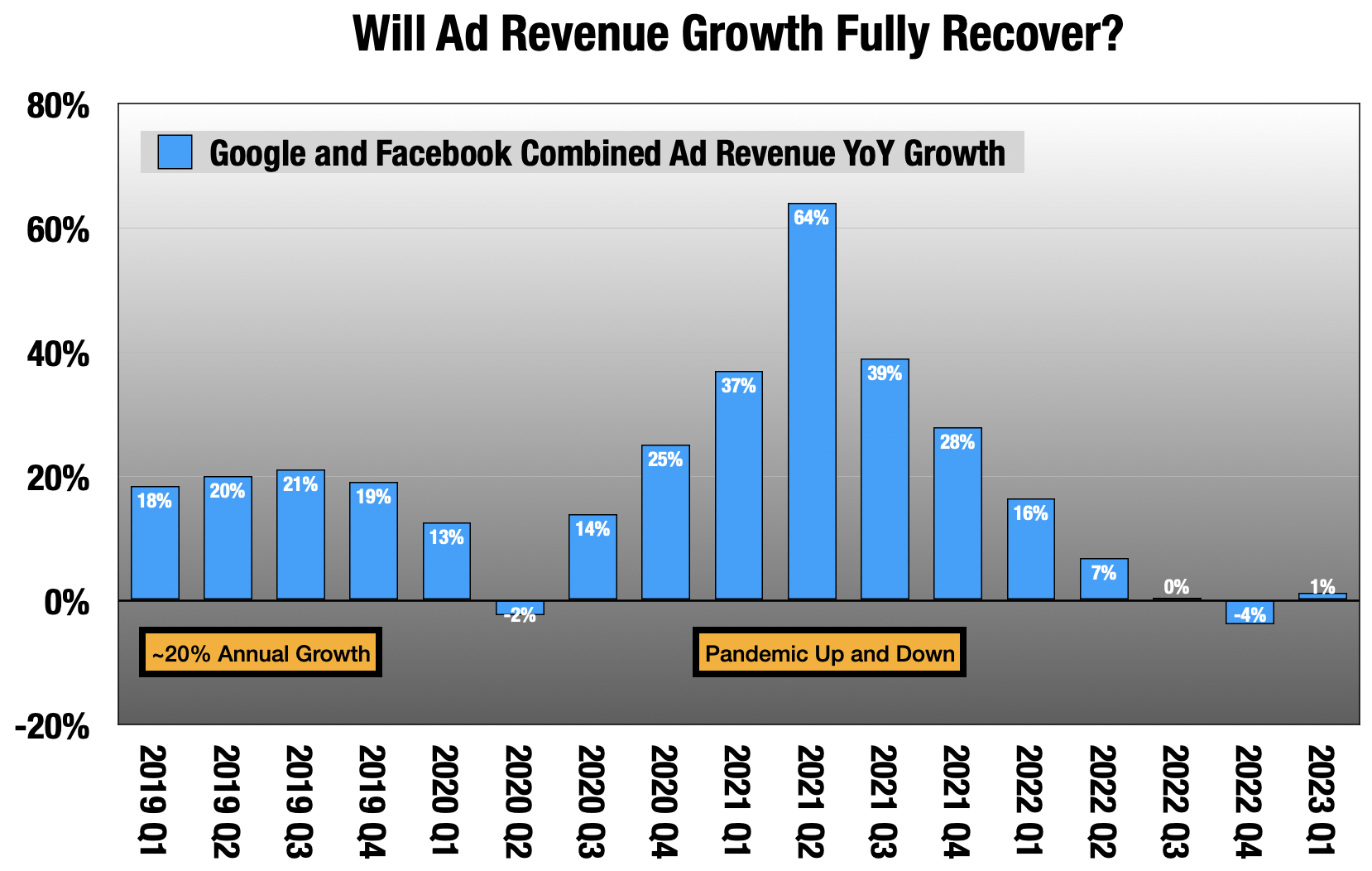
I think the days where we can count on Google for 15%-20% growth in the ad business are over. Ad budgets do not grow at 20% a year, and digital can only steal from other mediums for so long.
Both companies have relied heavily on surveillance advertising — following their users everywhere they go on the internet, whether in a browser or apps — in a free-for-all regulatory environment that is coming to an end. It began with changes made in iOS, but the EU is, as always, leading the way here on the regulatory side. They are slowly being cut off from the data hoses that made their ads so effectively targeted.
Both companies seem to realize they need new businesses that do not rely on surveillance advertising business models.
Finally, Google faces a range of antitrust threats. The most concerning is US v Google, which looks to break off Google’s ad network, acquired with DoubleClick. This is a case from the Justice Department and several states. Unlike some other recent antitrust claims, this one has a very clear, simple narrative. Google owns the largest ad exchange and is also the largest participant on that exchange. It’s as if Nasdaq (NDAQ) also owned the largest hedge fund. The network was 8% of Google revenue in 2022, but it also gives Google an unequalled view of the digital ad market, so losing the network would be a blow to all their other ad businesses.
Summing Up
- There has been a cost explosion in AI caused by spiraling model size and Nvidia’s data center GPUs.
- Bucking the trend, and violating the old laws of model scaling, Google released “significantly smaller” language models that seem to perform very well, and much better than their larger predecessor.
- The opportunity here is to offer performant language model APIs at significantly lower server-side costs compared to what OpenAI is offering, and make free open-source alternatives look less attractive.
- Running this at scale on TPU v4 also highlights the cost benefits versus Nvidia hardware to AI cloud customers.
- The smallest version of the new models can run on PCs or phones, opening up licensing revenue.
- While Google has had a lot of problems in the past turning good technology into profitable products, this all adds up to a coherent AI strategy, which they have never had.
- Google also faces other risks. Search has declined in quality. The high growth period for digital ads may be behind us. They may see their ad exchange lopped off by courts.
I had sort of lost interest in Google because of that last bullet. I think it’s especially troubling that they have let Search decline in quality as it has, by a death of a thousand cuts. This is the first thing in a while that looks like it could be a significant new business for Google, while also boosting Cloud from its also-ran position versus AWS and Azure.
It will come down to the real-world quality of these new models and future ones, and Google’s execution. My macro concerns persist, and execution has never been Google’s strong suit, so for now, I am still just watching from the sidelines.
Analyst’s Disclosure: I/we have a beneficial long position in the shares of MSFT, QCOM either through stock ownership, options, or other derivatives. I wrote this article myself, and it expresses my own opinions. I am not receiving compensation for it (other than from Seeking Alpha). I have no business relationship with any company whose stock is mentioned in this article.
Seeking Alpha’s Disclosure: Past performance is no guarantee of future results. No recommendation or advice is being given as to whether any investment is suitable for a particular investor. Any views or opinions expressed above may not reflect those of Seeking Alpha as a whole. Seeking Alpha is not a licensed securities dealer, broker or US investment adviser or investment bank. Our analysts are third party authors that include both professional investors and individual investors who may not be licensed or certified by any institute or regulatory body.
At Long View Capital we follow the trends that are forging the future of business and society, and how investors can take advantage of those trends. Long View Capital provides deep dives written in plain English, looking into the most important issues in tech, regulation, and macroeconomics, with targeted portfolios to inform investor decision-making.
Risk is a fact of life, but not here. You can try Long View Capital free for two weeks. It’s like Costco free samples, except with deep dives and targeted portfolios instead of frozen pizza.
