
Summary:
- Given past GPU needs, capturing the entire AI large language model market would increase revenue by $16 billion at the high end.
- However, this doesn’t factor in recent research released in the last 5 months, which in total implies decreasing GPU usage by a factor of 2/3.
- Deep learning chips built by big tech will also cut into NVDA’s market share.
- Taking all these facts together, even if NVDA additionally controls the entire AI large language model market, it will still trade at a P/E of 70x.
da-kuk
Introduction
Nvidia (NASDAQ:NVDA) came out with a blowout earnings report, guiding for revenues of $11 billion next quarter a 52% QoQ increase. Despite this positive news, relatively back-of-the-envelope modeling combined with an understanding of the tech behind large language models suggests that it will be almost impossible that NVDA grows into its valuation. Without a doubt, Nvidia will benefit from the artificial intelligence (AI) revolution. Despite a nosebleed 37x P/S valuation, not a day goes by without a thesis from the bulls and NVDA itself that the AI demand for graphical processing units GPUs will send NVDA earnings to the stratosphere. For example, Stanley Druckenmiller bought $430 million worth of NVDA. On Seeking Alpha Mark Hibben, a Seeking Alpha writer whom I greatly respect, argued that ChatGPT would be a huge windfall for NVDA. In Nvidia ChatGPT windfall, he quotes a Microsoft (MSFT) blog article:
This infrastructure included thousands of NVIDIA AI-optimized GPUs linked together in a high-throughput, low-latency network based on NVIDIA Quantum InfiniBand communications for high-performance computing.
The implication being the diffusion of large language models (LLMs) like ChatGPT would lead to a tsunami of graphical processing unit (GPU) demand. Another machine learning specialist said on behalf of Amazon (AMZN) at AWS:Reinvent: “for every $1 spent on training, up to $9 is spent on inference.” According to OpenAI: “The supercomputer developed for OpenAI is a single system with more than 285,000 CPU cores, 10,000 GPUs and 400 gigabits per second of network connectivity for each GPU server.” Training a model refers to finding parameters that allow the LLM to generate natural language that looks like it came from a human. Inference refers to the costs associated with humans querying an already trained language model and asking it to provide an output given an input. If OpenAI used 10,000 GPUs to train GPT3, AWS is obliquely claiming that it will take 90,000 GPUs to produce inference.
AI will increase GPU demand for sure, however given the 37x P/S ratio that NVDA commands, demand needs to be more like OpenAI buys 90,000 GPUs a year, rather than OpenAI buys 1000 GPUs here and 500 GPUs there. As a data scientist who is up to date on transformers and LLM state-of-the-art, this post will illustrate why the former is a pipe dream.
Before I discuss my thesis, I want to make clear, this is not a self-contained pitch about NVDA. I don’t know much about semiconductors and so I can’t discuss NVDA tech compared to competitors. GPUs are certainly the weapon of choice for training LLMs and Nvidia is the weapon of choice for GPUs, but this is not my expertise. Based on what I know, I can roughly guess what the demand for GPUs is going to look like, and this contradicts the argument made by NVDA bulls. Most of the bull cases I’ve read, hinge on the LLM and AI angle and so this piece is designed to address that. If you have a variant view based on something outside of AI, I’m not trying to challenge a thesis in that arena.
The GPU Costs of LLM Inference
I’m going to focus on the inference total addressable GPU market (TAM), and then discuss training demand for GPUs next. Semianalysis argued that cost per GPT-3 query was .36 cents, which is roughly in line with OpenAI’s pricing for GPT-3.5 turbo. Semianalysis argued that it was taking 3.5k HGK A100 GPUs to serve 200 million queries. Google serves 29 billion searches a day. Considering GOOG has 4.3 billion users and China has 1 billion internet users, adding China to the number of searches requires multiplying the Google number by 25%–as China doesn’t use Google search, but they do buy GPUs. To serve the 29*1.25 = 36.25 queries a day to an LLMs (highly unrealistic because most searches are quick and dirty 10s of tokens, while queries to LLMs are more nuanced and expressive), you would need 3.5*181 = 635k (HGK) A100s. Each A100 costs about $150k. This means that NVDA would require $96 billion to supply enough GPUs to process the whole Western Internet worth of LLM queries. In their article, Semianalysis estimates their number at $100 billion–not adjusted for China demand–but I think they have an unrealistically high estimate of tokens per query. That being said, the valuation still doesn’t work with $125 or $150 billion GPU TAM.
At first, this seems great for NVDA bulls. But keep in mind that this is the entire cost of GPUs (plus a markup for middlemen) based on essentially the world demand for LLMs. GPUs last 5-8 years in a server, so I’ll use a 6-year replacement cycle. Dividing the total annual revenue from LLM GPUs ($96 billion) by 6, implies that NVDA’s revenue will increase by $16 billion a year. This is an increase in revenue by 60%. That being said, a temporary increase higher than this steady state run rate, will be higher as companies have to build up the stock of HGK A100. Likely this is what we are seeing in the Q2 NVDA guidance. However, for valuation’s sake, the steady state revenue matters more, and that is between a $15 billion and $20 billion increase.
Now I will model profits due to this increase in revenue. Since R&D has been growing faster than revenues, I don’t want to punish NVDA for capital investment. Thus, a more reasonable case may take into account increased R&D costs to maintain market leading share. I add EBT before the one-time cost of R&D to get profits before research and development. Dividing by revenues, I get an earning before taxes + R&D margin of 52%. Out of this number, I will subtract average R&D costs and stock-based compensation. This results in profits of $15.4 billion. With a market cap of $931 billion, this results in a P/E ratio of 60.5x assuming all LLM revenue finds its way to NVDA and there are no improvements in GPU usage efficiency.
Improvements in Inference and Training Speed
A huge factor missing in this argument, missing in Semianalysis’ argument, missing in AWS:Reinvent, is that research will drastically reduce inference costs. In 2022, the AWS:Reinvent comment was roughly true. It looked like it would take a ton of GPUs to meet demand. However, one year is a long time in AI and a good deal of research is aimed at making LLMs more efficient. Quantization and related techniques allow one to run inference of a model the size of GPT-3 on a single GPU. This is a huge improvement over initial inference costs which required 8 GPUs. The basic idea behind quantization is using 4-bit floating point numbers instead of 32-bit or 64-bit numbers. This reduces the memory requirement by 8x or 16x per parameter. Tests suggest that this course graining of the parameter weights doesn’t have a negative effect on performance.
A second innovation is distillation. This idea is simple: train a large model on data, then simulate data from a large model to train a smaller model. The above-linked paper trained a model with 770 million parameters via distillation that outperformed Google’s state-of-the-art 540 billion parameter PaLM model. Quantization and distillation have been around for a few years, but these improvements, setting a new bar for inference efficiency, have all been written in 2023. Other innovations include pruning, sparse attention, and architectural improvements. The research people at AWS:Reinvent were factoring in 2022, pale in comparison to the explosion of LLM efficiency research that has occurred.
From the research linked, you can fit a 175 billion parameter ChatGPT style model on a single GPU. If you use distillation, you could probably run four 15-20 billion parameter distilled models with equal performance to ChatGPT on a single GPU (this is conservative as memory costs scale with parameters). None of this research was released before Semianalysis’ work, so they couldn’t have factored it into GPU cost. In order to modify the Semianalysis cost model, let’s say OpenAI has 200 million daily queries (the same number as assumed by Semianalysis), each query to a LLM takes roughly 20 seconds. Due to times of higher and lower demand, GPUs are only in use for an average of 15 hours a day. Putting these numbers together implies that 9400 GPUs can handle 200 million queries. So instead of using 3.5k HGK A100s (29k GPUs) to handle 200 million queries as implied by Semianlysis, you only need 10k GPUs with all this optimization. This reduces the total additional GPU TAM captured by NVDA by two-thirds, meaning predicted revenues will be $33 billion, from the first pass prediction of $43 billion. All this doesn’t include probably the most impactful innovation this year, flash attention, which was introduced last May, and is supposed to reduce inference time by 5x, and has now been implemented in the new Falcon models.
Of course, research is not standing still, just in May, META released MEGABYTE, which speeds up both training and inference while increasing the context window capacity significantly. A couple of days ago, SOPHIA was released, potentially reducing training time by a factor of 2. Techniques to make LLMs more efficient from both a training and inference perspective are ongoing and much of the low-hanging fruit is still left to be picked.
Training TAM
I haven’t talked about the GPU needs for training and the reason is that it’s small. It seems to have Cost OpenAI $5 million to train GPT-3, but inference costs per day are almost $700 thousand. Thus, it would take running GPT-3, 7 days before inference costs were larger than training costs. But on this front, there are continual improvements. Training costs are getting cheaper as models get smaller. The Chinchilla scaling laws paper by DeepMind GOOG basically derived a relationship between model size, data size, and computational cost. If you have x amount of data, you know how big you should make your model in order to minimize costs. What people quickly realized was, given the amount of data we had, our models were an order of magnitude too large. As a result, open-source performance looks like this:
Open Source Vs Proprietary LLMs (Vicuna)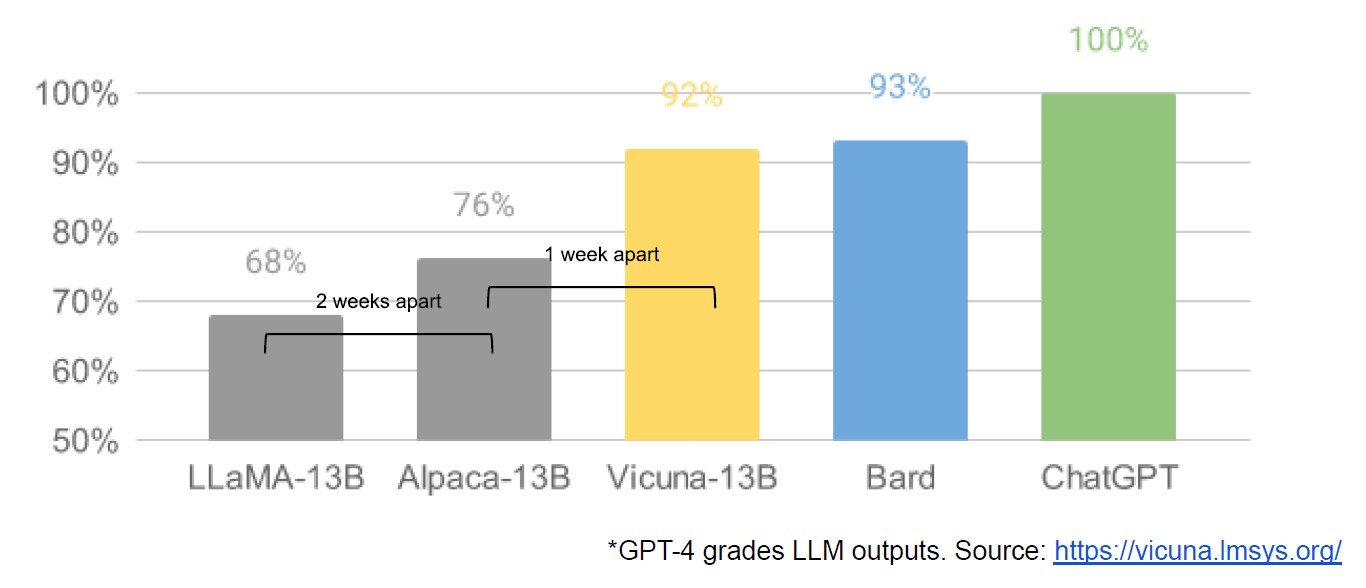
This chart was created by using GPT-4 to score the ouput of a given language model. ChatGPTs performance was normalized to 100%. Vicuna, a 13 billion parameter model, is within statistical equivalence with the 133 billion parameter Bard model trained by GOOG. Additionally, this model was created just 3 weeks after the weights of LLaMA were released by META and it cost $300 to go from 68% to 92% performance. Additionally, Mosaic released a system that trains models that perform as well as GPT-3, for $500,000, which is almost 10x less than GPT-3 costs. Of course, these models had something like 30 billion parameters which is 6x smaller than GPT-3. The Chinchilla paper implies smaller and smaller models as data increases, given constant costs. These cheaper training curves and the smaller models also indicate that inference costs will go down. Vicuna has 10x fewer parameters than Bard, so it roughly would require 10x less compute. If OpenAI was paying $700,000 a day from GPT-3 inference, Vicuna may reduce that to as much as $70,000 a day—also implying a 10x reduction in the GPU inference needs.
GPU Competitors
All this analysis assumes that NVDA will capture 100% of the machine learning GPU market, which to the first approximation could be accurate. However, competitors on the fringes are worth talking about. GOOG has a Tensor Processing Unit (TPU), which is designed for deep learning computations. I don’t imagine GOOG will sell the TPU, but will use it for internal LLM and cloud computing. Likewise, META recently developed (MITA), which serves the same purpose. Additionally, there are specialty GPU firms like Cerebus, which will take share in the high-end high compute market where much of the training of LLMs resides. AMD also has a chip that is not much used for machine learning due to NVDAs domination of the GPU programming language (CUDA). However, LLM inference does not require heavy reliance on NVDA’s GPU advantages like CUDA, which can give AMD an opening. Furthermore, we can assume GOOG and META will take a large share of their own LLM compute and share from some cloud compute—cutting out NVDA.
Reconciling My Forecast with NVDAs Guidance
NVDA forecasts quarterly revenue of $11 billion next quarter. Annualized this matches my TAM before GPU efficiency improvements. Considering this results in 52% QoQ improvements, this growth seems to suggest NVDA has more to grow above and beyond my additional GPU TAM. I argued the GPU needs due to LLMs are in total around $100 billion plus or minus $25 billion. If you are replacing the 16% that breaks down every year, you are never going to accumulate GPUs to match this stock. Thus, it’s not surprising that in order to accumulate GPUs you need to buy more than the $16 billion replacement cost. So it’s not surprising in the next several quarters that revenue is above the $40 billion run rate. It should moderate as GPU needs are fulfilled. Furthermore, given how recent the research cited is, it’s likely that most industry players have not implemented these improvements and so it’s not surprising the quarterly guidance currently resembles the TAM not adjusted for GPU efficiency research. These improvements will be implemented in due time.
Risks
The biggest risk to my thesis is further improvement in LLMs which require models that have more parameters and more GPUs to train. For example, Webush’s Dan Ives argues that AI will be an $800 billion market. If it only costs $100 billion to build all the GPUs necessary, and another 100 billion to handle management costs, this leaves 75% profit margins for AI, which will incentivize companies to build bigger and more expensive models thereby increasing demand for GPUs. That being said gross margins of (800-100)/800 = 87% are not absurd for a SaaS company and with the big tech oligopoly of LLMs, arguably most of the benefit of LLM will be captured by big tech and not NVDA. Even if larger LLMs are still profitable, based on the Chincilla paper, larger models may not be necessary for the foreseeable future if institutions cannot increase their compute budget. The Chinchilla paper extrapolates a log-linear relationship with respect to performance, and at some point, the exponential decrease in performance will no longer be worth the training cost–although there is not much evidence we are there yet.
Another risk is Chain-of-Thought and Tree-of-Thought prompting which prompts a language model multiple times and could take averages results in every human prompt, producing many calls to the LLM. I think businesses will understand that doing this ensembling will be computationally expensive with benefits that can be more cheaply provided to the end user by training a model with more data, more flops, and as a last resort–more parameters.
Conclusion
Under a condition that is beyond optimistic, I have shown that NVDA still will not grow earnings to justify its market cap. Factoring in recent GPU efficiency innovations, if NVDA captures the entire large language model GPU demand, revenue will grow from $27 billion to $33 billion dollars. Using the same profitability model as above, this comes out to $13 billion in profits. Thus in this scenario, NVDA trades at 60.5x earnings–even after assuming it captures 100% of GPU TAM. Even though there will be an increased demand in GPUs, I’ve also highlighted current research advances that will reduce GPU inference and training needs. I’ve pointed out competitors that may not fully challenge NVDAs dominance but may occupy some space when it comes to training deep learning models. For these reasons, I think NVDA is overvalued. I plan on analyzing a lot of companies by examining the math, statistics, and machine learning that helps them succeed. If you want me to analyze a company based on their machine learning tech, send me a DM, or write a suggestion in the comments.
Analyst’s Disclosure: I/we have a beneficial long position in the shares of META either through stock ownership, options, or other derivatives. I wrote this article myself, and it expresses my own opinions. I am not receiving compensation for it (other than from Seeking Alpha). I have no business relationship with any company whose stock is mentioned in this article.
Seeking Alpha’s Disclosure: Past performance is no guarantee of future results. No recommendation or advice is being given as to whether any investment is suitable for a particular investor. Any views or opinions expressed above may not reflect those of Seeking Alpha as a whole. Seeking Alpha is not a licensed securities dealer, broker or US investment adviser or investment bank. Our analysts are third party authors that include both professional investors and individual investors who may not be licensed or certified by any institute or regulatory body.