
Summary:
- First, this article discusses the history and technology behind large language models, especially transformer architecture and advances.
- Next, this article discusses the commercial implications for companies like Google, Amazon, Facebook, and Microsoft.
- Finally, this article discusses why big tech will benefit greatly from large language models, at the expense of everyone else.

Userba011d64_201
Introduction
Not a day goes by without news of another investor going all in on AI. Stanley Druckenmiller buys $430 million worth of NVIDIA (NVDA) and Microsoft (MSFT). Bill Ackman bets $1 billion dollars on Alphabet. Tepper also likes NVDA. Large language models (LLMs) have already set off a firestorm of innovation and captured the imagination of investors. As a data scientist, I am writing this post to explain the implications of LLMs on the economy and investments. I hope to provide color to the future of big tech, but I won’t be proposing any long or short ideas. I will argue that other than the possibility of market share realignment in search, LLMs will disproportionately benefit large tech firms. This part will focus on discussing the technology and history behind the development of LLM. The second upcoming part will focus on the consequences of LLM for the financial markets.
An LLM is a machine-learning model with many parameters that work with language. For example, if you haven’t seen ChatGPT, play around with it here. ChatGPT is a computational model, trained on a lot of the text from the internet so that can answer questions and engage in conversation in a way that is difficult to distinguish from a human. Because of the data it was trained on, ChatGPT can write language quickly, and, since it was trained on the internet, seems to know a lot of useful knowledge, although it has been known to BS answers given more difficult questions. The most common LLMs are transformer-based models that generate text. You can also have models that evaluate text, return embeddings, and work with images, videos, or sound.
Embeddings and BERT
Embeddings are one of the most important building blocks of modern transformers. The famous word2vec paper used a neural network-based matrix decomposition technique—similar to principle components analysis—to convert each word into a vector representation. For example, the word “happy” may be converted into the vector: [.34, .55,.-12….76]. This is a way to teach a machine learning model “meaning”. The famous example given in the word2vec paper is that the vector for king, minus the vector for man, plus the vector for woman, is close to the vector for queen, suggesting different areas in this vector space correspond to different meanings.
Word2vec was state-of-the-art natural language processing for a long time. Then came recurrent neural networks. And finally in 2017, came the transformer, which was a huge innovation underpinning all current LLMs. A transformer is a particular type of machine-learning model that works well with language. For example, a transformer could take in an input of a paragraph of text providing information and asking a question. Then it could return text answering the question. The core of the transformer model is the attention module. At each word of the output, the attention model calculates a weighted average of all the inputs. If you had a sentence: “Jane Doe was tired of walking given her age of 84” and you asked a question, “How old is she?” The attention module might pay attention to the words “Jane Doe” and “84” in the original text when generating its answer.
Here is a diagram of an encoder transformer:
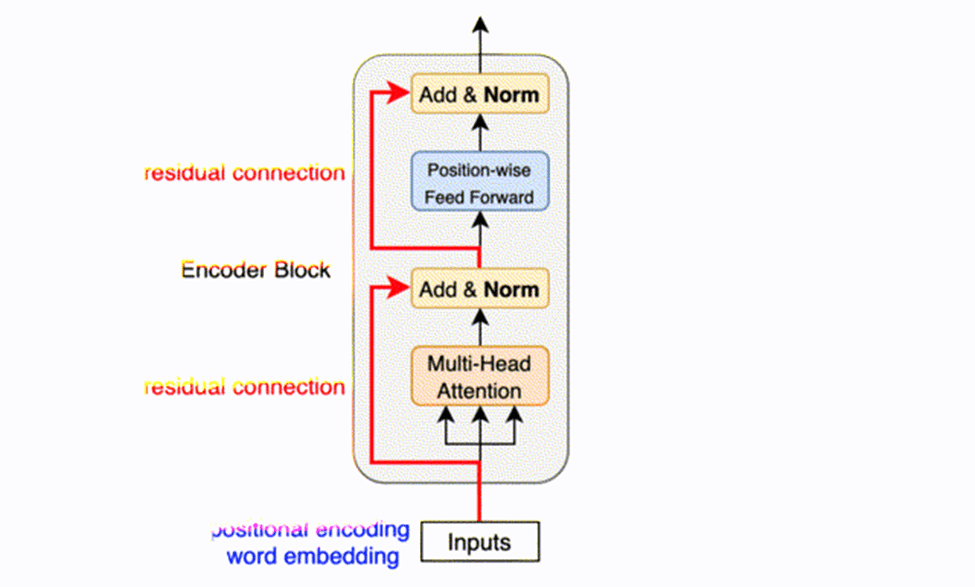
A Diagram of a Transformer Encoder (KiKaBeN)
Your input gets converted into an embedding and is fed into the attention mechanism. After normalizing the attention output, that gets fed into a feed-forward neural network. Think of this as a flexible function with many parameters that can produce almost any output desired but can be optimized to give you optimal information on what words should be outputted.
BERT is one of these encoder transformers. When people talk about Google (GOOG,GOOGL) already using AI in their search models, they are talking (usually unknowingly) about BERT. BERT converts word inputs into contextual embeddings, which are like word2vec embeddings, but BERT can differentiate between the same word in different contexts. For example, the word “bank” here: “He deposited money in the bank.” And this context: “He rowed the boat by the bank.” Embeddings, in general, are useful to search, because you can pre-convert the entire internet of words into embeddings. When you type a search into Google, it will convert your search into embeddings. Thus, it doesn’t need to match search queries word for word but will also take into account meaning in embedding space. Being able to retrieve similar documents to a phrase in question is powerful, but BERT is still a long way from being able to produce a custom answer–pages long like ChatGPT. This is what the current version of transformers can do, living up to the LLM name.
From BERT to ChatGPT
There are two problems with BERT: It can’t generate text and it has only 110 million parameters which isn’t enough to model human language nuance well. BERT is trained as a masked language model. That means given some text, you mask random words in the text and ask BERT to predict the masked words give the (forward and backward) context. For example, “Jane Doe is 84 years old”. If I masked “years”, I would use the context from before (“Jane Doe is 84”) and after (“old”). In this process, it learns a good embedding for the word “years”.
Unfortunately, if you want to generate text in the form of answering questions, you can’t use text from after the word you want to generate. Thus generative language models use causal masking. For example, take the phrase, “Jane Doe is 84. However, she still goes to the gym.” If you want to teach a casual language model to generate text, you mask: “Jane Doe is 84. Mask, mask…”. Thus you mask all words after “84.”. When the language model produces “she”, you reveal the mask and tell the model it was incorrect. Then it takes in the input with the next word produced“, “Jane Doe is 84. However, mask mask mask…”. You have masked an additional word, but it was “she”. That feedback goes into training the model. Now your model conditions its output on the additional revealed word “However,”. This time the model guesses “she” again, and this time it is correct. The next word is produced and the model is then conditioned on “However, she”. In this way, the model uses all the information before any text to generate the next word. When ChatGPT is implemented in the real world, there is no ground truth. So you might have a question like, “What is Jane Doe like?” and the model may produce the first word, “she”. Then you condition ChatGPT on the word “she” to produce the next word “is”, then condition the third word on “she is”. In this way, ChatGPT can generate text by autoregressively conditioning on the previous word.
This in a nutshell is GPT. I skipped over some stuff like softmax, decoder, and perplexity evaluation, but you now know more than a data scientist on the cutting edge at the beginning of 2018. The big event at this time is GPT-3 by OpenAI, which has 175 billion parameters. Besides the parameter count, looks architecturally like the original GPT, which is a basic encoder/decoder transformer. GPT-3 is 1000x the size of BERT and that difference in parameter is the main reason GPT-3 is more powerful than BERT. ChatGPT took the work of GPT-3 and added finetuning techniques to make it production ready and able to communicate with humans without producing toxic output. The process of training ChatGPT and any other subsequent LLM follows these three steps:
- OpenAI used common crawl data (i.e., much of the internet) along with Wikipedia, and books to pre-train the model.
- Following this pretraining, they finetuned their model. For example, ChatGPT prioritizes question and answering and not just generating text. For a pair programmer, like Codex, it is finetuned to generate code.
- Then using Reinforcement Learning with Human Feedback (RLHF) they adjust the model to match human preferences for low toxicity and politeness. I will discuss this next.
Reinforcement Learning with Human Feedback, Scaling Laws, and LLaMA
There were three innovations that led to the proliferation of large language models: Reinforcement Learning with Human Feedback (RLHF), Scaling Laws, and the open-sourced Facebook (META) model: LLaMA.
First RLHF by OpenAI and DeepMind Google. One problem with a model like GPT-3 is it was trained on the entire internet. As such, it picks up anti-social behavior from places like 4-chan/8-chan and the dregs of Reddit. One way to make the model less toxic is to apply RLHF. With RLHF, you ask a bunch of people to evaluate the output of a GPT-3 prompt. Usually, it involves selecting which of two different prompts is preferred, where preferred is defined as something like “most helpful” or “least offensive” etc. Using this information, you build a reward model that attempts to predict (using something like an Elo score) a numerical score for each output, where higher scores are more likely to be selected “most helpful” compared to lower scores. Then you use Reinforcement learning (RL), to optimize the model to produce preferred prompts more likely. In this way, you constrain the model to produce outputs that are helpful or non-toxic, at least according to the preferences of the human evaluators.
The second breakthrough was the Chinchilla scaling laws paper by DeepMind GOOG. Training a bunch of LLMs of different parameter sizes and different data set sizes illustrated a relationship that tells the optimum amount of training time given data size and model size. Thus, if you know you can train your model for x number of floating point operations (FLOPs)—this is cost—you can calculate the data size and model size, which will give you the best result. This paper demonstrated they could get better performance than GPT-3 with a model almost 1/3 the size but 4x more data at the same FLOPs cost.
The third breakthrough was the LLaMA work by META. This was just another LLM paper released in February. Like most other big-tech LLMs, it outperformed state-of-the-art models at the time. That was not surprising from a big release LLM. What is important about LLaMA was that its weights and architecture were accidentally released to the public. The most time-consuming and costly step is pre-training. It costs 4-5 million dollars to pre-train ChatGPT and potentially 100 million to develop when including research and labor, so it’s not surprising the tech giants wanted to keep proprietary ownership of models like GPT-3. Thus, it was great for the open-source community to have access to LLaMA’s weights. Paradoxically it was good for META too, as a generation of open-source LLM programmers will have cut their teeth on META’s model–in addition to META’s PyTorch being the dominant deep learning programming library. LLaMA’s release led to a large proliferation of open-source techniques based on this massive model trained with 1000s of GPUs. Fine-tuning techniques were introduced allowing for training LLaMA scale models on a single GPU. Different techniques like sharding allowed for faster training on fewer GPUs. Even techniques like gradient accumulation were reintroduced to allow for training LLMs on a single GPU. Quantization techniques and distillation allowed you to run models as powerful as GPT-3 on a single GPU. This has huge implications for stocks like NVDA. However since there is so much to unpack, I posted an NVDA feature article using much of this information. The other companies I have less conviction on, so a discuss them all here. I start with the implications for GOOG search.
Consequences for Google Search
One argument that is bandied around is that running large language models requires significantly more resources than traditional Google search. For example, SemiAnalysis writes:
This means that a search query with an LLM has to be significantly less than <0.5 cents per query, or the search business would become tremendously unprofitable for Google.
They ultimately argue that LLM costs in search will eat into GOOG’s search margins, “We estimate the cost per query to be 0.36 cents.”
This is backed up by ChatGPT’s gpt-3.5-turbo cost:

GPT 3.5-turbo Cost (OpenAI Pricing)
GPT-3.5 costs .2 cents per 1000 tokens. I would guess the average Google search is roughly 25 token inputs and maybe 200-700 token output–if output information and not a list of links–is provided. A .1 or .2 cent cost per search will–based on SemiAnalysis’ estimate–cut search profit margins by 25%. However, this is an unrealistic worst-case scenario. First, quantization and distillation will push this cost down. I am not sure what gpt-3.5-turbo has implemented, but SemiAnalysis’ cost estimate didn’t seem to incorporate these innovations fully. Given the higher costs baked into GPT-4, I would be surprised if these cost innovations have been passed down to the consumer. Second, most search doesn’t require the use of an LLM. For example, “where can I get a blood test?” An upgrade to a model like BERT, at essentially 0 contribution margin, can classify whether a search needs an LLM or not. My unscientific guess would be 90% of current searches don’t require an LLM.
That being said, the introduction of an LLM will likely open up additional search-like queries, for example, people asking an LLM to write code to scrape data on the internet. I think it’s possible the addition of the new market will make up for the lost margin on searches that need LLM input. However forecasting that is near impossible, at least for me.
The SemiAnalysis article does point out that MSFT and OpenAI could cut into GOOG’s search business. I don’t have a definite answer for this. You should ask people like Druckenmiller or Ackman why they are betting on who they are betting on and note that they are on opposite sides of the bet. LLM could certainly be the disruptive innovation that realigns market shares. When GPT-3 first came out I thought a realignment in the search was more likely. Now Google’s Bard is arguably better than ChatGPT. I don’t think it matters if Bard is a little better or a little worse than ChatGPT. In order to steal meaningful share from incumbents you need a product that is 10x better and ChatGPT. However, GPT-4 is better than BARD/GPT3.5 by a good amount, but given some time, I’m sure GOOG will have an answer to it. More likely than not, Google will be fine, as big tech almost always is able to find a way to capitalize on innovations even if they cannibalize their main business lines.
The main takeaway here is there will be some moderate increases in cost as LLM answers more search queries, but that could be outweighed by the increase in LLM queries that GOOG could charge a lot for. OpenAI is charging $20 a month for GPT4 access. GOOG might lose some market share to OpenAI MSFT search, however, GOOG is well positioned to introduce their own state-of-the-art LLM, so stealing share from GOOG will likely be difficult.
The Moat of Big Tech
A second piece released by SemiAnalysis was the infamous Google has no moat article. The basic argument is that no one has a moat regarding LLMs in big tech and open source will produce close to or better LLMs that big tech companies. I am skeptical since the only tech subsector I can think of where open source is the dominant player is server operating systems. Often tech firms and open source have a symbiotic relationship, but in almost all cases, big tech has profited from new tech innovations originating from academia, open source, or big tech.
The one thing investors don’t get about machine learning is that the algorithm is not the moat. There are probably 1000s of data scientists who can team up to train LLMs that perform on par with Bard or GPT-3. OpenAI, GOOG and META, have many of those teams working in-house, but open-source innovations suggest a good number of those people code outside that ecosystem.
After the release of LLaMA, open-source developers quickly improved upon the quality of the models. Here is a chart that is supposed to strike fear in every tech company CEO:
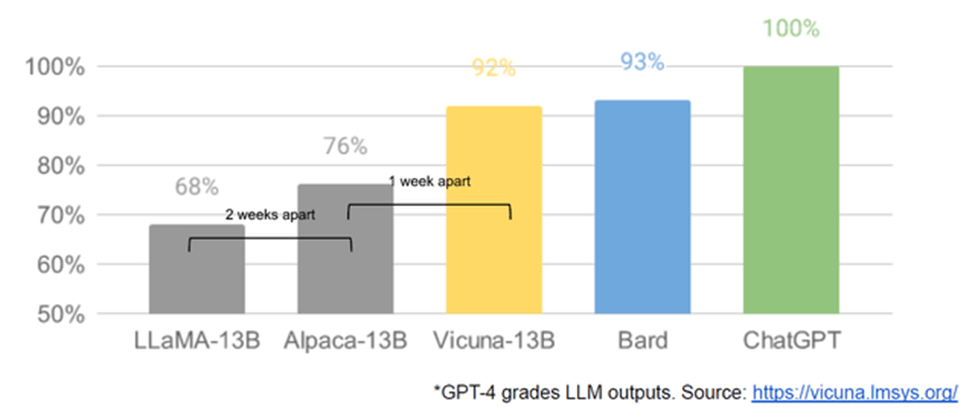
Open Source Performance Closes the Gap with Proprietary Models (Vicuna)
From the release of LLaMA weights, it took three weeks to get a model that is within statistical noise of the performance of GOOG’s production LLM, Bard. Bard has 133 billion parameters and Vicuna only has 13 billion. This has implications for LLM cost a la GOOG search as mentioned earlier. Vicuna’s main advantages over Alpaca was a longer context window (how many words you can put into a transformer at one time) and a 40x larger dataset. They also use 70k user-shared conversations from ShareGPT.com. Data is the reason for Vicuna’s outperformance.
GOOG, MSFT, META, and AMZN have more proprietary data than perhaps almost any other organization out there, including many governments. Maybe Bard doesn’t use flash attention. Doesn’t matter what that is. Any open-source innovation can be adopted by big tech. Then they can leverage their proprietary data on top of publicly available data. Using the Chinchilla scaling laws, they can spin up a model that has more parameters, more data, and a larger compute budget—creating a virtuous feedback loop that exponentially improves the performance of their LLM. You want to train a code generation LLM, MSFT has its own codebase, and the codebase—public and private—on GitHub. META has advertising and social media data. GOOG has advertising and search. AMZN has transaction data. It is hard to see open source finding the quality and quantity of data to match private companies. And even if they do, by nature of it being open source, the big tech firms will use the data to augment their proprietary stock.
As the Google has no moat article mentioned, the biggest beneficiary of the open-source community was META. They released their large language model and thousands of people improved upon it and META didn’t pay anyone a cent. It’s not as if innovation is unidirectional always flowing from the open-source community to walled gardens. It is in big tech’s interest to release some of their work—to mine for improvements, encourage familiarity with their ecosystem, and to build goodwill. It seems to be in big tech’s interest to release some models while holding back some data and maybe specific models trained on proprietary data. Algorithms aren’t the moat, data is and the open-source community is at this point more effective at innovating on LLMs than big tech is.
Maybe there is no 10x difference or even 2x difference between open source and big tech LLMs. However, 90% of all data online has been generated in the last 2 years. I’m sure there is an effort to build multimodal LLMs that take advantage of images, video, and audio. The increase in data will benefit the organizations that can collect and augment this data and increase the size of models. Additionally, data for specialized models like code-generating models, marketing/companion chatbots, AI secretaries, reside predominantly in the walled gardens of tech companies.
The main takeaway here is big tech doesn’t have much of an algorithm moat compared to academia and open source. They do have a moat with the sheer amount of data they have collected over the time they have been in business. Academics may not have the money to train a 100 billion parameter model, the old fashion way (i.e., without the tricks I mentioned), but there will always be start-ups funded with venture capital that could challenge MSFT, META, and GOOG on the algorithmic front. But that hardly matters as the sheer amount of proprietary data makes the LLMs that big tech has more powerful than open source alternatives.
Conclusion
In this article, I provided a background to how LLMs work. Then I provided some high-level analysis on the effect of LLMs on different sectors—especially tech. The world of LLMs is fast moving and it is impossible to predict with any accuracy far out into the future. General trends and dynamics can be gleaned with a thorough understanding of the technology. If you want me to analyze a company based on their machine learning tech, send me a DM, or write a suggestion in the comments.
Analyst’s Disclosure: I/we have a beneficial long position in the shares of META either through stock ownership, options, or other derivatives. I wrote this article myself, and it expresses my own opinions. I am not receiving compensation for it (other than from Seeking Alpha). I have no business relationship with any company whose stock is mentioned in this article.
Seeking Alpha’s Disclosure: Past performance is no guarantee of future results. No recommendation or advice is being given as to whether any investment is suitable for a particular investor. Any views or opinions expressed above may not reflect those of Seeking Alpha as a whole. Seeking Alpha is not a licensed securities dealer, broker or US investment adviser or investment bank. Our analysts are third party authors that include both professional investors and individual investors who may not be licensed or certified by any institute or regulatory body.