
Summary:
- Nvidia Corporation spent nearly two decades working on hardware and software to be ready for AI’s big moment in 2023. It’s no accident they are at the center of it all.
- But this all puts a huge target on their backs because they are taking all the money. They are stealing margin from customers, and customers’ customers.
- The resistance to Nvidia is proceeding on 3 tracks: non-GPU hardware, smaller models, and new software.
- Nvidia’s moat is that they have the only complete hardware-software suite, and have been the default for AI research since 2012. They will be hard to knock off their perch.
Justin Sullivan/Getty Images News
Nvidia Is Taking All The Money
The main thing Nvidia Corporation (NASDAQ:NVDA) makes are graphics processing units, or GPUs. But the “graphics” part is a bit of a misnomer. What GPUs do so very well is computationally expensive floating point math. This allows computers to have high-resolution monitors with high frame rates — graphics. It’s the most common use for GPUs.
Around 2005, Nvidia realized that while graphics may be the most common thing that requires heavy duty floating point math, it is far from the only thing. So they began a long journey that now puts them at the center of all AI. They developed software that allowed people to do things with Nvidia GPUs besides graphics, beginning with CUDA in 2007.
In 2012, they got the initial break they needed. The first pretty good image recognition AI, AlexNet, got built on Nvidia GPUs and software, and blew away rivals at the annual ImageNet competition. From that point on, Nvidia hardware and software became the AI research default for everyone except Alphabet Inc. (GOOG, GOOGL) aka Google.
Since then, Nvidia has split their GPU development into two tracks. The ones that go into PCs and crypto mining rigs, and the data center GPUs. The PC GPUs are very expensive, topping out at around $1,600. The data center GPUs are $10,000-$15,000. I have seen them sell as high as $40,000. Nvidia gets something like a 75% gross margin on the data center GPUs, unheard of in hardware.
But that’s what happens when you have what is substantially a monopoly in AI hardware and software.
The other big thing that has happened since 2012 is that Nvidia GPUs and software have enabled explosive exponential growth in model size.
Keep in mind, that is log scale on the Y-axis, so this is massive exponential growth in the shaded “Modern Era” area. (IEEE)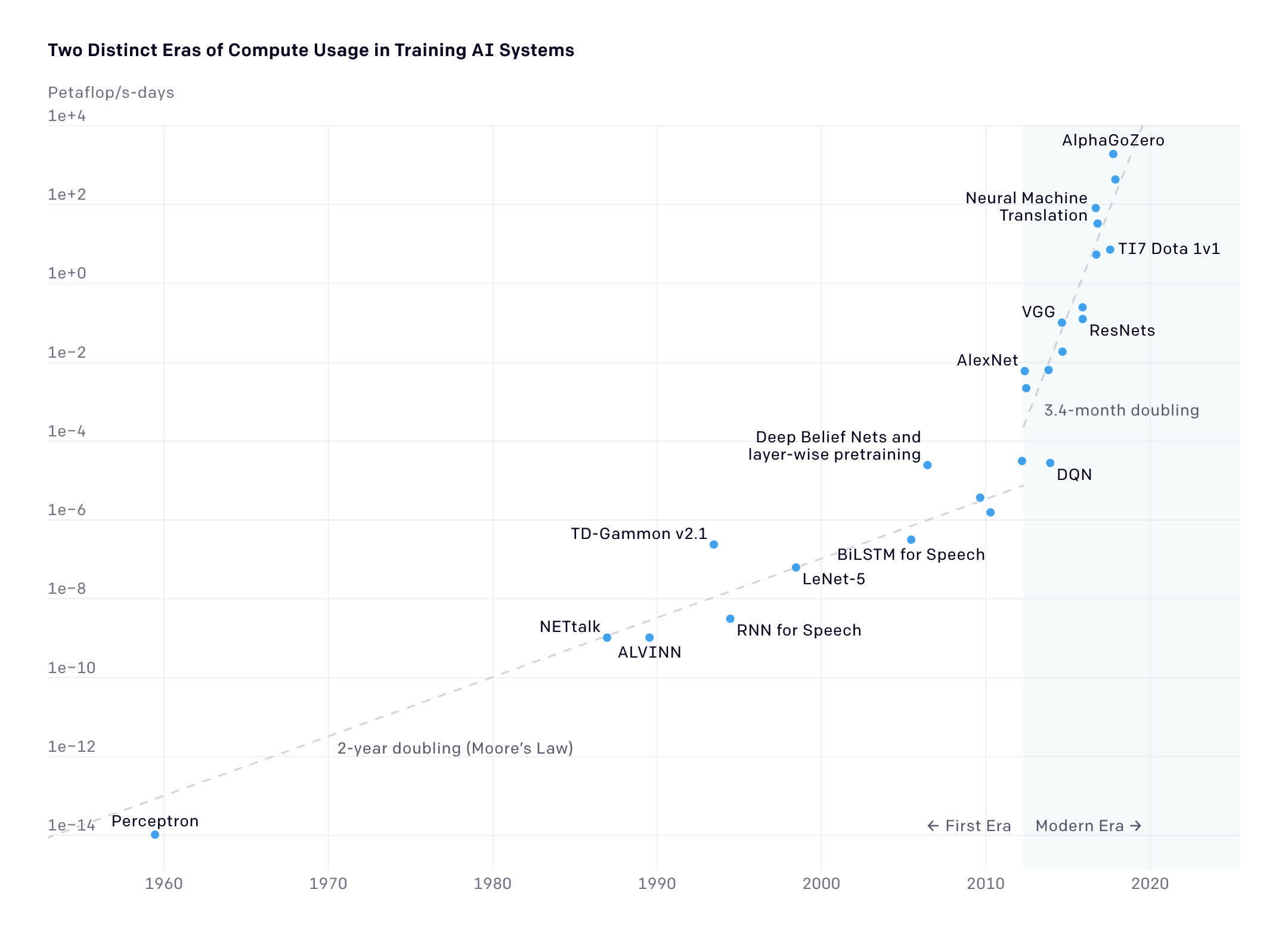
In the years leading up to 2012, model size grew roughly at the Moore’s Law’s rate of doubling every two years. Then you see what happens after everyone adopts Nvidia GPU machine learning in 2012 — the line shoots up, doubling every 3-4 months. That chart ends before ChatGPT. The largest model there is AlphaGo, which is very good at playing the Chinese board game, Go. In 2021, the largest model was still playing games.
Model size is important because the costs to build and run these things in production scale exponentially with model size. GPT-4 is somewhere in the range of 3-6 times as large as its predecessor, GPT-3.5. But OpenAI charges 15-60 times more for the GPT-4 API. What’s more, they are not yet offering the best version of GPT-4. Microsoft Corporation (MSFT) Azure, where all OpenAI is hosted, still doesn’t have enough Nvidia GPUs to pull that off, and what customer could afford it at scale anyway. They are holding back on other services as well for lack of GPUs.
Let’s take a quick example. I asked ChatGPT to write a poem about the upcoming Fed meeting. You can read the exchange here. It’s a 3-sentence prompt, followed by a 28-line poem in response. Let’s see what that silly exchange would cost over at the OpenAI API:
The last Google revealed Search metrics was 2012 when it was 1.2 trillion searches. I use 3 trillion as a lowball estimate of where that is today. (ChatGPT Plus, token calculator software, OpenAI API pricing)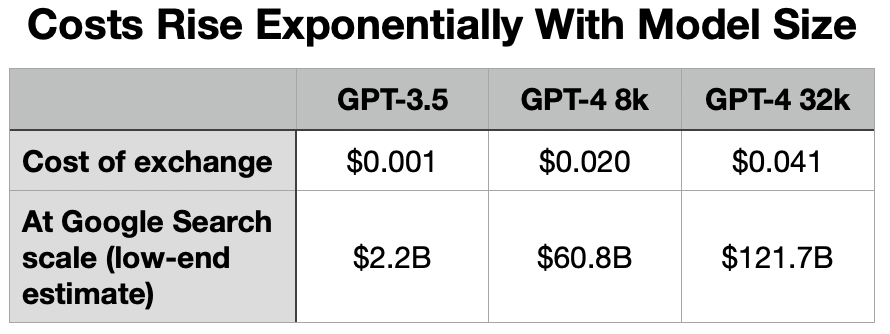
The reason for that huge price rise is Nvidia data center GPUs. The third column is the service that they still cannot offer for lack of GPUs.
These trends set up when these very large models were still in the research phase. Building them is very expensive, but that pales in comparison to running them in production at scale. All of a sudden, the economics have changed, because we are now out of the research phase for many things. By defaulting to Nvidia hardware and software for a decade, and making model size grow very fast, everyone is backed into a corner now. Nvidia is taking all the money.
And I mean from everyone:
Microsoft quarterly reports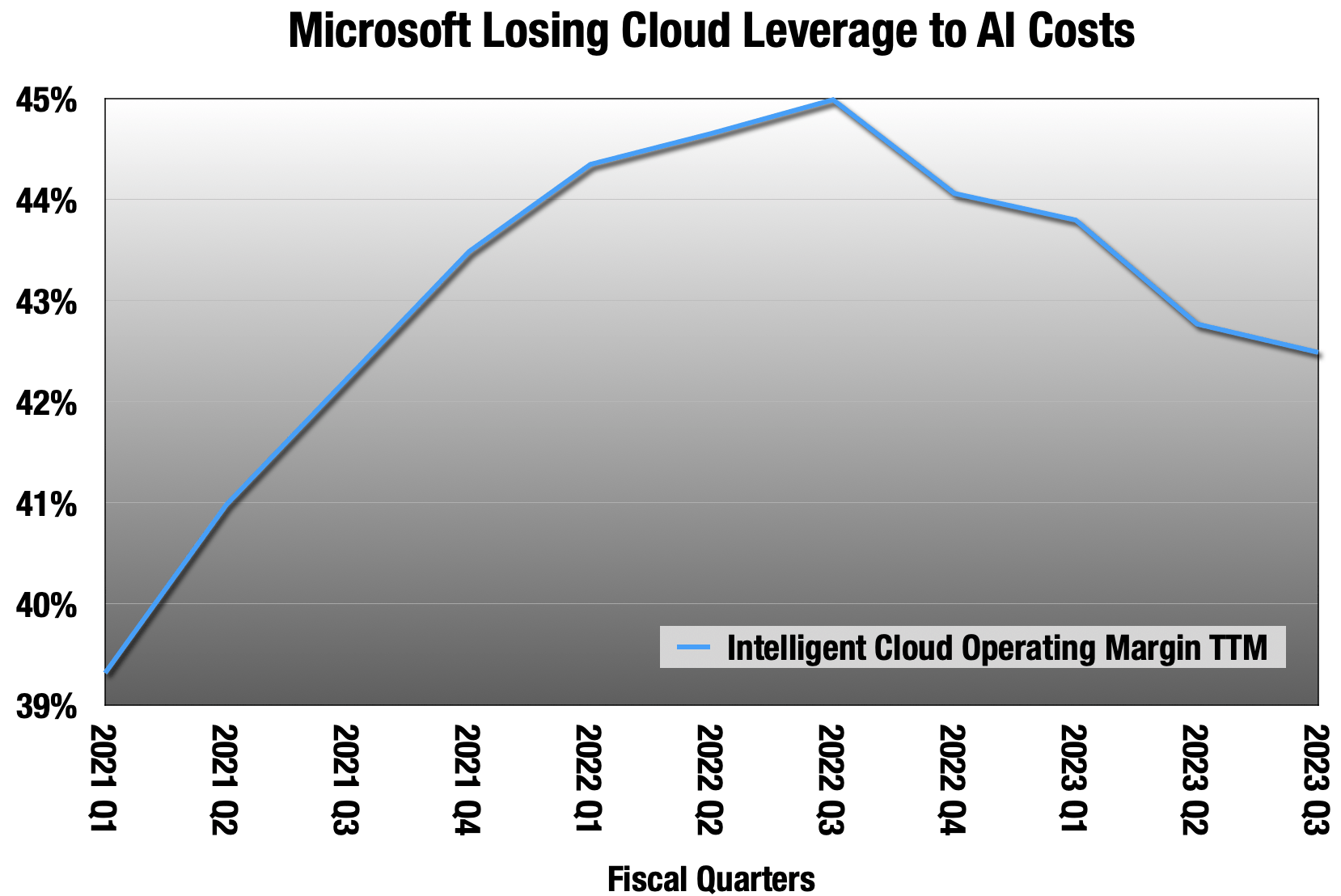
Microsoft was gaining operating leverage in their Intelligent Cloud segment for many years with rapid top line growth. That ended when they had to buy a lot of GPUs to put ChatGPT into production. Their cloud operating margin is down 4 quarters in a row now, and the reason is Nvidia’s 75% gross margin on those data center GPUs.
Nvidia’s DGX H100 server (Nvidia)
When you price out an AI server like the Nvidia DGX H100 above, it’s shocking the extent to which Nvidia is taking all the money.
Approximate guesses at what Nvidia pays for their 3rd-party components (Analyst research)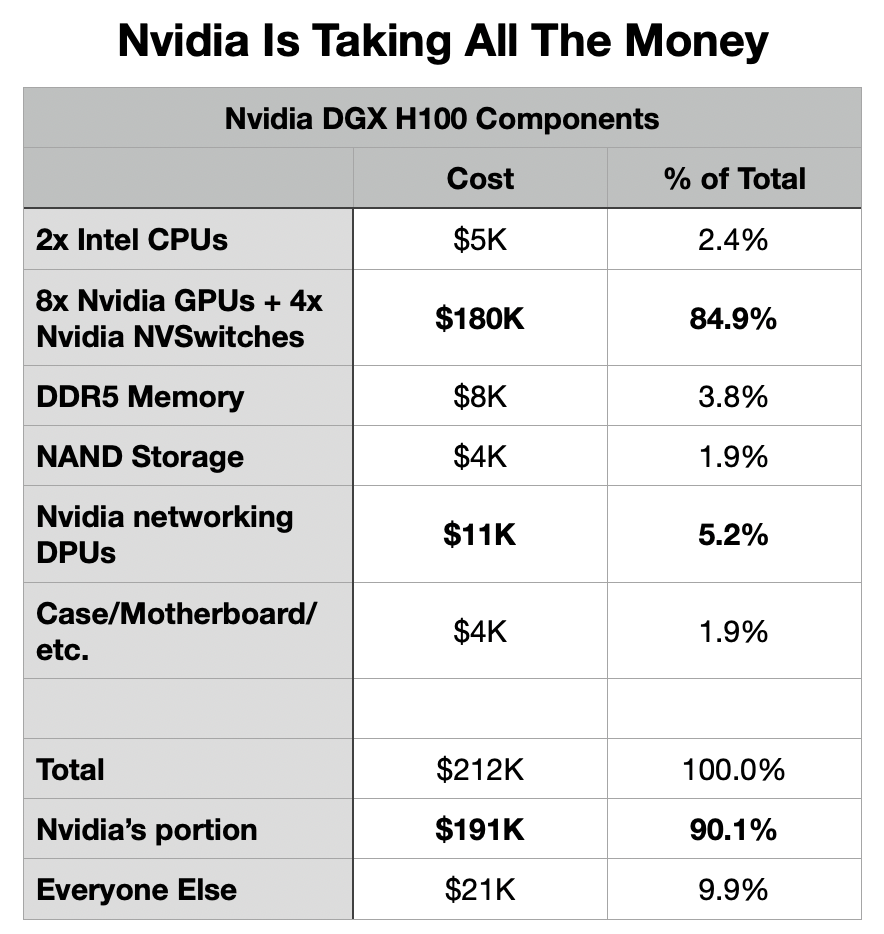
That’s some approximate sales costs that go into Nvidia’s DGX H100, their AI supercomputer building block. It’s sort of the gold standard for AI servers now, and about 90% the materials by sales value are Nvidia. And that doesn’t even include their markup on the server.
If you were making your own very high powered server, you could save money by skipping that markup, using a cheaper CPU than the most expensive like Nvidia does, or by using less memory and storage. You can save a lot of money eschewing Nvidia’s networking DPU hardware and substituting cheaper hardware from Broadcom Inc. (AVGO) or Mellanox (oh, wait, that’s also Nvidia), though it may cause bottlenecks if you do. But you are still stuck with something close to a $180k Nvidia bill for 8 H100 GPUs, and the 4 NVSwitches that connect them together.
Nvidia is taking all the money because they have spent nearly two decades getting ready for this moment in 2023. But it puts a huge target on their backs. I don’t know that I have ever seen anything as ripe for disruption as Nvidia’s AI hardware dominance. But that does not mean it will happen any time soon. Their moat is that they have the only complete suite of hardware and software that has made it very easy for researchers to make them the default choice since 2012. But the default is costing everyone too much now that we have moved these very large models into production.
So what is everyone doing about it? So far, three things:
- Hardware: “AI accelerators” are alternative hardware that can do the same work at much lower cost.
- Model size: In a very recent development, researchers are trying to make smaller models work better, dramatically decreasing the need for GPU compute.
- Software: Something that can drain Nvidia’s moat by making training and inference hardware-independent.
AI Accelerators: On The Wrong Side of the Moat
This is sort of a loose grouping of a few different kinds of hardware. The category began in 2015 when Google’s AI training needs exceeded the capabilities and supply of Nvidia GPUs of that vintage. That year they debuted the Tensor Processing Unit, or TPU, for internal use. Versions 2, 3 and 4 are available to rent on Google Cloud for up to a 40%-50% savings over cloud GPUs to do the same work.
There are a few ways these things are designed, but they mostly do the same thing under the hood — fake that very computationally expensive floating point math with computationally cheap integer math. This leads to lower mathematical precision, but a lot of research shows that outside of scientific applications, most AI doesn’t need the very high level of precision that Nvidia GPUs bring.
So it’s a bit of a cheat, but one that seems to work pretty well. Now we see AI accelerators from AMD/Xilinx (AMD), Qualcomm (QCOM), Intel Corporation (INTC), and others. Google Cloud has the TPUs. Along with hosting the Intel accelerator, AWS from Amazon.com, Inc. (AMZN) also has their own. Microsoft is reportedly building one for Azure, with the idea of putting all OpenAI on it, maybe with help from AMD.
The cloud providers in this group have to tread lightly. On the one hand, they want to stop handing over margin to Nvidia. On the other hand, for the foreseeable future, they need to buy a lot of Nvidia GPUs, and Nvidia routinely has supply issues. It’s a delicate dance.
The big thing holding the hardware back is the Nvidia software moat. We’ll talk about that below.
Model Size: Small Is Beautiful
You saw the fantastic growth in model size after 2012, doubling every 3-4 months. For years, that pattern was bigger and bigger. At OpenAI, for example:
- GPT-1 (2018): up to 117 million parameters
- GPT-2 (2019): up to 1.5 billion parameters
- GPT-3 (2020): up to 175 billion parameters.
- GPT-4 (2023): OpenAI isn’t saying, but probably pushing a trillion or more.
That was fine while everything was in the research phase, but now that these same very large models are moving into production, the costs are staggering. OpenAI still has not even been able to get the best version of the GPT-4 API into production because Azure doesn’t have enough GPUs for that yet.
What I’ve been telling you is not a secret. I think everyone started seeing where this was headed last fall. “Bigger is better” doesn’t make sense in a commercial setting right now. All of a sudden, small is beautiful.
This began the day ChatGPT was released. There were many companies, large and small, who had been working on natural language processing. ChatGPT was a slap to the face. It was bigger and better than what they had, and in one moment they all realized that they were way behind. Commence panic.
Last year everyone saw Stability AI get a lot of traction with their open source Stable Diffusion image generator, so many decided to open source what they had and see what happened next. Facebook of Meta Platforms, Inc. (META) was one of them, open-sourcing their LLaMA language models that range in size up to 65 billion parameters about a third the size of GPT-3, and 9x-18x smaller than GPT-4. Then researchers at Stanford made a version, Alpaca, that would run on any hardware.
And we were off.
The pace of open source development can be pretty staggering when the community gets excited about something, and there are a huge number of applications being built on top of Alpaca and other open models. Others are working on making the models work better while keeping them small.
Most importantly, these models can run on consumer hardware, PCs and phones, and they are free, as in beer. There is a chance that the dividing lines in foundational models will not be company versus company, but commercial versus open source.
Google also noticed. The big news at I/O was that they announced a language model that was smaller than its predecessor, and also much better.
- LaMDA (2021): up to 137 billion parameters.
- PaLM (2022): up to 540 billion parameters.
- PaLM 2 (2023): up to 340 billion parameters according to an unconfirmed leak, but “significantly smaller” in Google’s telling.
This is the first time I can remember models getting smaller, not larger. The smallest of the 4 PaLM 2 models can run on PCs or phones.
All of a sudden, small is beautiful. But GPT-4 remains the best language model, also the largest and most expensive to run. That favors Nvidia. But now many have set about the task of making smaller language models work better. Google is doing it in the training process. The open source people are fine tuning what is available to them, primarily the LLaMA/Alpaca models.
So the threat to Nvidia here is much reduced GPU compute intensity for the same work, and more of it running on consumer hardware.
Software: Draining the Moat
The non-Nvidia AI software infrastructure is fragmented and has holes in it, and building a system around non-Nvidia hardware can run you into dead ends. Google remains the exception again, as their internal tools have all been built around TPU since 2015. They need to turn those into cloud services, and they have started that.
The most important part of all this to Nvidia is not the hardware, which is all pretty impressive stuff and where the money comes from. The software they have been working on for nearly two decades now is their moat, because it is the combination of the two that make them so easy to choose. Then once you build on Nvidia hardware and software, you are sort of stuck with running it in production.
For years, non-Nvidia researchers wrote software for their own purposes, and now the landscape is unsuited for a production environment. This is going to be the hardest piece to disrupting Nvidia.
The best whack at it so far comes from Chris Lattner and is new startup, Modular. Lattner is sort of a legend in software circles. As a grad student, he wrote LLVM, which became the basis for many software compilers in wide use today. LLVM’s innovation was a modular structure that allowed it to be extended to any programming language and hardware platform. He led the team that built the Swift programming language at Apple Inc. (AAPL), followed by stints at Google, Tesla, Inc. (TSLA), and everyone’s favorite RISC-V company, SiFive. Modular has funding from Google in their A-round.
One of the things Modular is working on is an inference engine, which runs models in production, that has a modular design like LLVM. It can be extended to any development framework, cloud or hardware. No matter how a model was built, it can be dropped into the Modular inference engine, and work on any hardware in any cloud. At least, this is what they are promising.
This is exactly what is required to drain Nvidia’s moat, and likely Modular’s intention. This will be the hardest part of disrupting Nvidia.
How Nvidia Fights Back
It’s Nvidia against the world: their own customers and their customers’ customers. Nvidia can only keep doing what they have been doing and resist complacency. Anyone who watched their recent presentation at Computex Taipei can attest to the fact that they are not in any way standing still.
But they also need to be wary of how disruption happens. It’s usually not a direct challenge, like a rival GPU in this case. More often, it’s cheaper and less performant hardware.
The classic case is IBM (IBM) and Intel. In the 1970s, IBM’s customers looked at the “microcomputers” being built around hardware from Intel and others and told them they were not interested. So IBM listened to their customers. But Intel silicon was good enough for hobbyists. Intel took the cash flows from that and reinvested it into making their CPUs better.
When Visicalc, the first PC spreadsheet software came out, all of a sudden these microcomputers were good enough for business work, and IBM’s customers were interested. IBM became an Intel customer, their first big one. Then this happened:
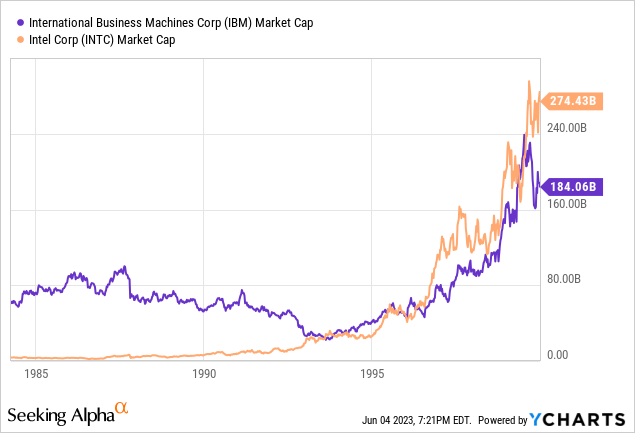
This is a very roundabout way of saying that in addition to what they are doing, I think Nvidia has to make an AI accelerator to protect that flank eventually, even if it undercuts their margin and growth. If they don’t do it, someone else may do it for them.
Nvidia’s Valuation
A wide variety of opinions (Seeking Alpha screenshot)
This is a topic of much discussion. My year-forward bull-case model with some generous assumptions still has them trading at around 50 years of year-forward earnings. The growth story is real — that’s in the model. But the Nvidia Corporation valuation has gotten out ahead of even a very bullish case.
There is an analogy going around that Nvidia in 2023 looks a lot like Cisco Systems, Inc. (CSCO) in 1999-2000.
- The leading hardware infrastructure providers for a new wave of tech: the internet in 1999 and AI in 2023.
- Despite fast growth already, Cisco hit a 200+ P/E ratio in 2000. Nvidia was at 204x last Friday.
The Cisco bulls were largely correct about their business prospects after the 2001 recession ended, with strong growth until the financial crisis. Let’s look at that period in the stock:
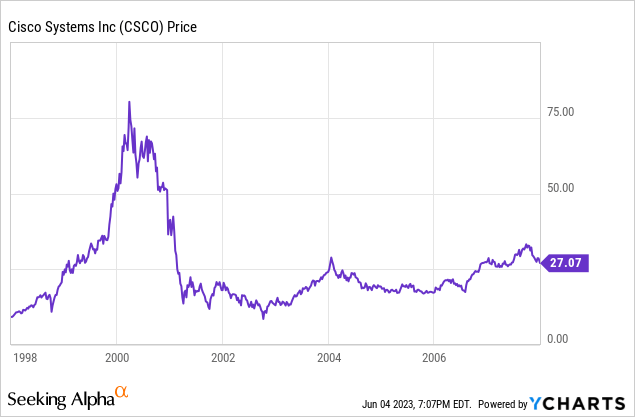
So, in the first place, valuations matter, and we all need to keep that in mind as the decade-plus of very loose financial conditions comes to an end, at least for now. Cisco has never gotten back to that 2000 peak.
But I think the analogy falls down on closer analysis. Cisco was the market leader for sure, but they had vigorous competition. As of now, Nvidia has the field to themselves. That can only last for so long. How long? As of last week, it is literally a trillion dollar question.
I also can’t help but notice that the Cisco chart looks very much like the Gartner Hype Cycle.
Highlighted: generative AI, which is mostly what we are talking about here. (Gartner)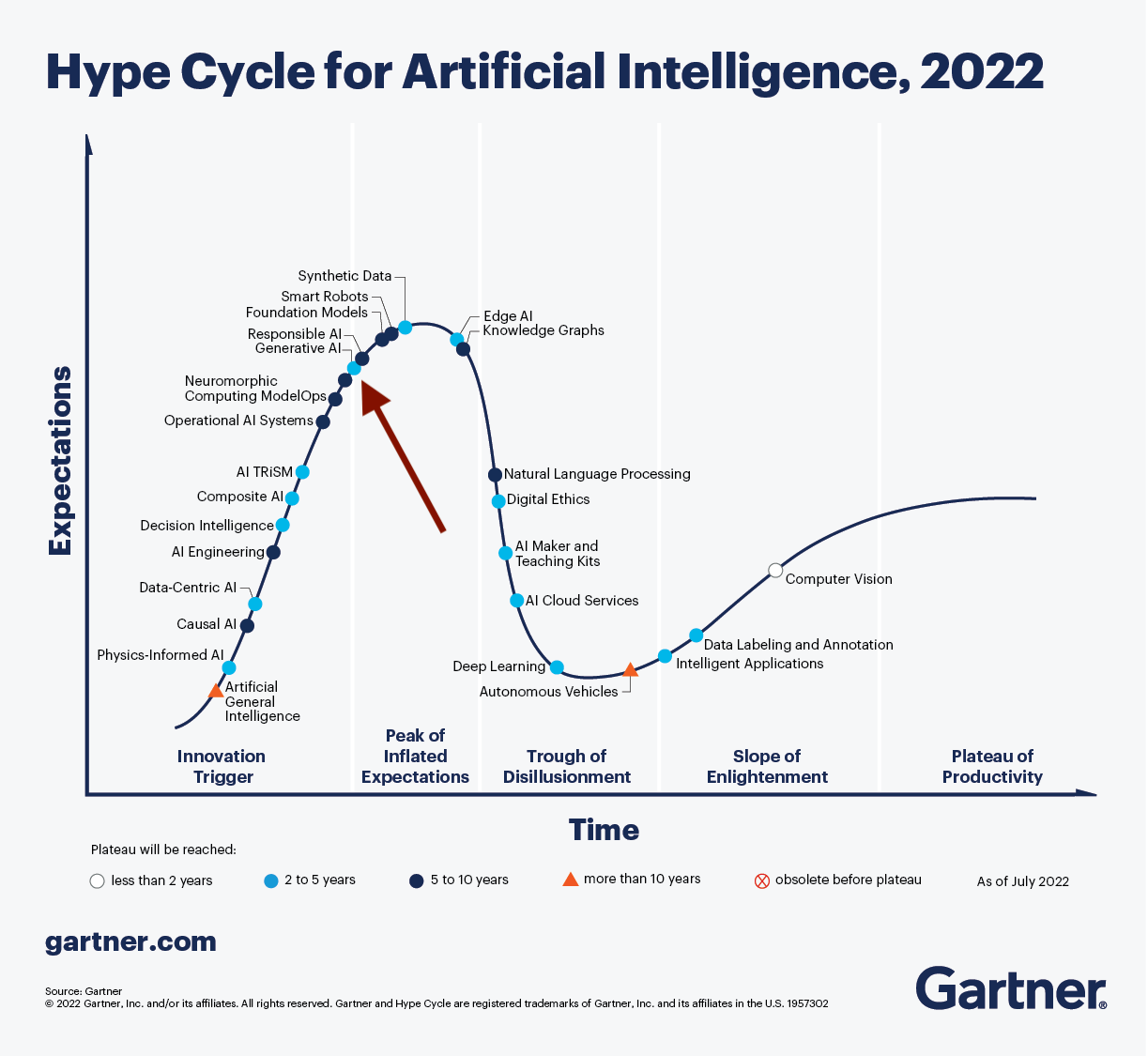
This chart comes from July 2022, just before the Cambrian explosion of ChatGPT. Generative AI, highlighted, is near the “Peak of Inflated Expectations.”
Nvidia’s price assumes this sort of growth will keep going, and the 5 considerable risks will not happen.
- Crypto mining revenue never recovers. I rate this as highly probable, but is not priced in.
- AI investment turns out to be a bubble like crypto investment. I rate this as a low probability, but a very large risk to the story that is not priced in.
- Something disrupts Nvidia’s AI hardware dominance and they are forced to shave that 75% gross margin. I rate this risk as very, very probable in the long term, with the trillion-dollar question being what that long term is. 2025? 2030? 2035? Later?
- There may be a recession late this year or early next year. I rate this as roughly a 50-50 shot.
- Moore’s Law has hit another roadblock, and performance gains are going to be more costly until that clears up. Silicon is reaching its limits as a material.
I was a longtime Nvidia bull until it became a meme stock in 2020. It now operates under its own logic and rules, rules I’ll admit I don’t fully understand where 50 years of forward earnings make sense.
Anyway, I prefer to invest during the “Trough of Disillusionment,” as Gartner calls it in the chart above. I bought Cisco in 2002.
For now, I’ll just be watching closely. This is the most interesting conflict in business, and I can’t wait to see where it goes next. The pace of developments is spectacular.
Analyst’s Disclosure: I/we have a beneficial long position in the shares of AAPL, MSFT, QCOM either through stock ownership, options, or other derivatives. I wrote this article myself, and it expresses my own opinions. I am not receiving compensation for it (other than from Seeking Alpha). I have no business relationship with any company whose stock is mentioned in this article.
Seeking Alpha’s Disclosure: Past performance is no guarantee of future results. No recommendation or advice is being given as to whether any investment is suitable for a particular investor. Any views or opinions expressed above may not reflect those of Seeking Alpha as a whole. Seeking Alpha is not a licensed securities dealer, broker or US investment adviser or investment bank. Our analysts are third party authors that include both professional investors and individual investors who may not be licensed or certified by any institute or regulatory body.
At Long View Capital we follow the trends that are forging the future of business and society, and how investors can take advantage of those trends. Long View Capital provides deep dives written in plain English, looking into the most important issues in tech, regulation, and macroeconomics, with targeted portfolios to inform investor decision-making.
Risk is a fact of life, but not here. You can try Long View Capital free for two weeks. It’s like Costco free samples, except with deep dives and targeted portfolios instead of frozen pizza.
