
Summary:
- AMD’s Advancing AI presentation on the performance capabilities of its next-gen chips was a critical gauge for the sustainability of its growth outlook.
- The company predicts the AI accelerator TAM alone will grow at a 60% five-year CAGR through 2028, reaching $800 billion.
- And AMD’s deepening foray across key aspects of the AI infrastructure ecosystem, spanning software, hardware, and cluster level systems is likely to reinforce its revenue share grab over the longer-term.
- This will underpin an anticipated uplift in its growth trajectory that remains underappreciated at the stock’s currently traded levels.

JHVEPhoto
The AMD stock (NASDAQ:AMD) has been gradually regaining momentum after concerns of AI fatigue surged in the last earnings season and plagued markets. The chipmaker’s latest “Advancing AI” presentation for its next-generation “end-to-end AI strategy” further reinforces AMD’s increasing capitalization of emerging opportunities in the nascent field.
In addition to hardware, AMD’s latest launch event has also dedicated greater airtime to its software capabilities and deepening foray in cluster level systems. This largely differentiates from launch events in the past, and shines a light on AMD’s increasingly comprehensive full-stack computing capabilities following its series of acquisitions in recent years.
Although AMD’s AI revenue share remains a far cry from market leader Nvidia’s (NVDA), its Instinct series accelerators are making significant strides based on updates from Advancing AI. The next-generation MI325X accelerators, fitted with industry leading HBM3E memory, will begin volume production later this year and start shipping in 1Q25. Paired with its adjacent reach into AI opportunities across server processors, client CPUs, semi-custom chips, supporting software and systems, AMD is well-positioned for a greater share of the burgeoning AI TAM.
An Overview of the AI TAM
AI is rapidly encompassing all technologies and industries. And this trend will inevitably benefit all of AMD’s core segments, spanning data center, gaming, client and embedded. The company projects the TAM for AI accelerators alone to reach $400 billion by 2027, and $500 billion 2028, which would represent a 60% CAGR from 2023. Management has also exhibited confidence in the potential for further upside as the relevant computing cycle remains in its early stages of deployment.

AMD Advancing AI Keynote Presentation
Much of this opportunity will be fuelled by increasing compute demands for training and fine-tuning LLMs, and inferencing. The rapidly changing landscape of AI infrastructure needs will be a key driver of impending demand for next-generation AI accelerators. This is consistent with fast-evolving developments in foundation models most familiar to the mass market today, jumping from GPT-3 most known from the early debut of OpenAI’s ChatGPT to now GPT-4o which includes reasoning capabilities. All of these workloads will only increase inferencing requirements with greater power, memory and compute intensities.
And AMD has a unique answer to these demands. It comes primarily from its proprietary chiplet architecture designs that have been underpinning AMD’s hardware innovations. While this competitive advantage of AMD is rarely talked about, it has been a key function in enabling the accelerating rate of performance gains and cost efficiencies in its products.
The chiplet architecture has essentially overcome the restrictions of Moore’s Law. By “distributing traditionally monolithic SoC designs into multiple smaller chiplets”, AMD is able to better scale its innovations and develop more powerful processors with a faster time-to-market. This is evidenced in AMD’s decision for an annual cadence on its AI accelerator roadmap, which is complemented by its proprietary chiplet designs. The sizable performance gains in every new generation of EPYC server processors is also corroborative of efficiencies unlocked by the chiplet approach. This has been key to delivering greater power and cost efficiencies to customers without compromising on performance.
The chiplet approach has also underpinned AMD’s foray in semi-custom silicon. Due to the relative ease of adding and subtracting chiplets, the approach has helped AMD excel in leveraging its existing innovations and further tailoring them for specific customer needs.
While merchant processors are expected to represent the majority of the AI accelerator TAM, differing end-market demands – particularly in enterprise settings – create room for custom silicon opportunities as well. Industry peer Broadcom (AVGO) has recently indicated a $20+ billion opportunity in custom ASICs, with further expansion at a 7% CAGR through 2030. With AMD positioned to supply both merchant GPUs and custom ASICs, it benefits from a two-pronged reach into emerging AI accelerator opportunities, which will further optimize its revenue share over the longer-term.
Instinct Roadmap

AMD Advancing AI Keynote Presentation
AMD remains committed to the one-year cadence for its AI accelerator roadmap announced during Computex 2024. In the latest Advancing AI presentation, management has provided further details for upcoming upgrades to the MI300 series and their vision for next-generation MI400 series accelerators by 2026.
MI325X
Management confirmed the MI325X will start volume production later this year, and begin shipping from system OEMs like Dell (DELL) and Super Micro Computer (SMCI) in 1Q25. As discussed in our previous coverage on AMD, the upgraded MI300 series accelerator will consist of massive memory capacity. It features 256GB of next-generation HBM3E memory, almost double of that in the Nvidia H200 GPUs, to unlock “leadership inference performance” across key workloads.
The upcoming MI325X is unlikely to be short of demand, given robust adoption for its predecessor. During Advancing AI, management disclosed that Meta Platforms’ (META) Llama 405B model “now runs exclusively on MI300X for all live traffic”, providing substantial validation to AMD’s technology. Robust MI325X update uptake will likely be further reinforced by AMD’s strategy for the new accelerator to leverage the same socket as its predecessor, thus improving ease of adoption. Expectations of a higher sticker price for the MI325X is also expected to unlock incremental margin accretion for AMD’s data center segment.
MI350 Series
The MI350 series will start shipping in 2H25. They will be based off of AMD’s next-generation CDNA 4 architecture, which is expected to deliver 35x better inference performance than its predecessor. Despite the architectural shift, the MI350 series will remain compatible with the same socket as the MI325X and MI300X, allowing existing customers to better scale upgrades.
The MI350 series will include up to 288GB of HBM3E memory and offer substantial performance gains in AI compute. Specifically, the MI355X is expected to almost double the performance in processing FP6 and FP4 AI workloads compared to the MI325X. The MI350 series will be manufactured on the 3nm process node by TSMC (TSM), and is expected to be better positioned in competing against Nvidia’s Blackwell platform in terms of cost effectiveness, performance gains, and power efficiency.
MI400 Series
Details regarding the MI400 series remain at the high level during the Advancing AI keynote. Management has reiterated expectations for the MI400 series to launch in 2026 based on AMD’s “CDNA Next” architecture.
Based on the innovation cadence observed across the broader semiconductor industry, the MI400 series accelerators are expected to consist of next-generation HBM4. This will better position AMD’s accelerators in handling increasingly memory intensive workloads. The go-to-market timeline for the MI400 series also coincides with the anticipated completion of ZT Systems integration at AMD, pending closure of the transaction expected in mid-2025. This positions MI400 series for becoming AMD’s first accelerator to rollout in the form of silicon to AMD-built cluster level systems, competing directly against Nvidia’s HGX and DGX solutions across hyperscaler and enterprise deployments.
Software
Complementing this innovation roadmap will be increased prioritization over AMD’s software capabilities – particularly its ROCm open-source ecosystem. Improvements to ROCm in the last 10 months have unlocked significant performance leaps. The latest ROCm 6.2 beats the ROCm 6.0 by 2.4x on average in inferencing popular generative AI models, and 1.8x on average in training. Compatibility with popular AI ecosystems like PyTorch, TensorFlow, ONNX and OpenAI Triton has also streamlined hardware migration and adoption of AMD products for customers.
AMD has also made several software acquisitions – including Mipsology, Nod.ai, and most recently, Silo AI – to further improve the hardware-agnostic experience for customers and bolster ROCm’s AI capabilities. The software-hardware strategy is expected to further reinforce adoption of AMD’s ecosystem for facilitating the AI transformation.
Next-Generation EPYC Strategy
While earlier years of data center build-out to facilitate cloud migration has underpinned AMD’s EPYC strategy, the next-generation of deployments will place a greater focus on optimization for existing infrastructure. This will be key to mitigating AMD’s exposure to obsolescence risk, as next-generation data center build-outs focus on accelerated computing to facilitate AI workloads.
During the Advancing AI keynote, AMD has provided greater details on the performance specifications of its next-generation Zen 5 EPYC “Turin” server processors announced at Computex 2024. EPYC Turin will consist of 150 billion transistors, with up to 192 cores and 384 threads. There will be two iterations, one manufactured on the 4nm process node and the other on 3nm. Consistent with its increasing focus on optimization for customers, the Turin processors will leverage the same SP5 socket as the Zen 4 Genoa/Bergamo series to ease adoption for existing infrastructure upgrades.
Combined with substantial TCO improvements, the EPYC Turin is expected to become industry’s “highest performing server CPU”. This further casts a shadow over rival Intel’s (INTC) latest Emerald Rapids and upcoming Sapphire Rapids Xeon processors, and underpins additional share gains for AMD.
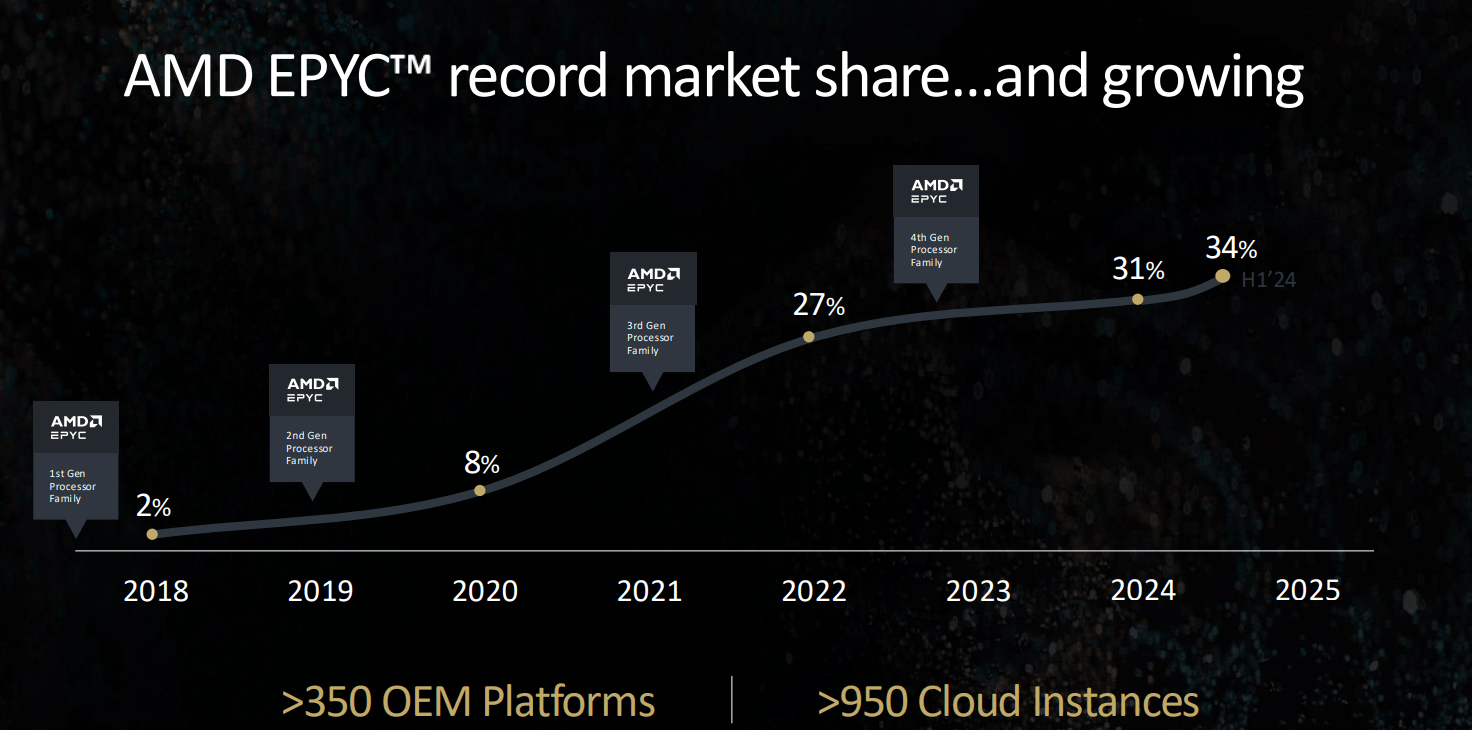
AMD Advancing AI Keynote Presentation
Specifically, the EPYC Turin server processors are expected to unlock competitive TCO by offering of up to “60% more performance at the same licensing cost” as Intel Emerald Rapids. This further catapults the optimization capabilities previously observed in the Zen 4 EPYC Genoa processors. Genoa deployments to date have enabled as much as 50% TCO reductions, while also delivering the same level of compute with “45% fewer servers compared to the competition”. In addition to TCO improvements, EPYC Turin has been designed to unlock material AI performance leaps on CPU of up to 3.8x compared to Intel Emerald Rapids.

AMD Advancing AI Keynote Presentation
Taken together, AMD expects an average consolidation ratio of 7-to-1 for each legacy server processor replaced by EPYC Turin. This is expected to reinforce adoption by better addressing increasing CIO demands for more compute and support for AI workloads without materially changing the “physical footprint and power needs of current infrastructure”. The next-generation EPYC server processors will also enable legacy data centers to operate more efficiently, while also “making room for next-generation workloads, whether they be CPU or CPU and GPU based”.
The shift in focus to optimization for AMD’s core EPYC portfolio is a prescient move in our opinion. This will give AMD a competitive advantage in preserving, and potentially gaining market share in a diminishing TAM amidst the secular transition from general purpose to accelerated computing over the longer-term.
Penetrating Cluster Level Systems
It is no surprise that AMD has been following its rival Nvidia’s footsteps in bolstering hardware-software full stack capabilities given its slew of acquisitions in recent years. As discussed in our previous coverage, AMD’s latest M&A activity includes its intentions to acquire server systems designer and manufacturer, ZT Systems.
Although the ZT Systems transaction is not expected to close until mid-2025, AMD is fixed on pushing forward with its foray in “cluster level systems design”, nonetheless. This will add another piece to AMD’s broadening end-to-end AI ecosystem and further its reach into emerging growth opportunities.
Specifically, AMD is well-positioned for substantial synergies as the integration of ZT Systems completes around 2026. This timeline would coincide with the anticipated launch of the next-generation MI400 series accelerators. The MI400 series’ integration with AMD-built cluster level systems and software is likely to drive further optimization in performance and cost considerations for customers. This strategy is likely to bolster AMD’s competitive advantage against Nvidia’s current DGX and HGX systems, and also further its differentiation from Intel.
Revisiting Fundamental and Valuation Considerations
AMD’s Advancing AI innovation keynote reinforces our forecast that its data center segment will continue to be a key revenue share gainer. And spending across its key hyperscaler customers, spanning Microsoft (MSFT), Amazon (AMZN), Google (GOOG / GOOGL) and Meta Platforms, remain strong. The cohort has earmarked more than $200 billion for capex this year, with Bernstein estimating $160 billion of which will go towards AI infrastructure.
Strong data center adoption trends are further complemented by the emerging AI PC adoption cycle. And AMD’s Ryzen PRO AI makes a competitive choice in the premium segment, especially with the upcoming PC refresh cycle and integration with Microsoft Copilot+ next year. This is expected to further AMD’s client CPU share, particularly in commercial end-markets which have “traditionally been underrepresented”.
And AMD has been internally bolstering its commercial go-to-market capabilities, primarily in the design of Ryzen AI. Specifically, the third generation Ryzen AI Pro “Strix Point” CPUs are optimized for “enterprise productivity, immersive collaboration, revolutionary creation and editing, and personal AI assistance”, targeting workplace requirements. The company also plans to better leverage its server CPU partnerships as a gateway to penetrating client CPU opportunities in commercial end-markets.
Non-data center sales growth is expected to be further complemented by the emerging embedded segment recovery. Although management’s latest update expects improving order patterns in 2H24 to be a “little bit more gradual than everyone would like”, we are placing greater focus towards longer-term semi-custom opportunities instead. This is consistent with earlier discussed expectations for greater adoption of custom silicon in the ongoing AI transformation, which AMD can capitalize on thanks to its proprietary chiplet approach and FPGA capabilities acquired through Xilinx.
Taken together, we expect AMD revenue to expand at a 14% five-year CAGR through 2028. Data center sales will continue to be the fastest growing revenue stream for AMD, driven primarily by robust uptake for both its EPYC server processors and Instinct accelerators. This will be reinforced by continued improvements made to AMD’s software capabilities to unlock greater performance and cost efficiencies for customers, as well as incremental synergies with the addition of in-house cluster level systems design. All of which are expected to drive incremental scale and sustained margin expansion for AMD into the long-run, which is critical to cash flows underpinning its valuation outlook.
Author
Our price target for the stock remains unchanged from the previous analysis coming out of the Advancing AI keynote. We expect the stock to reach $200 apiece. The price target is driven primarily by expectations for an upward re-rate in AMD’s growth trajectory, given its deepening reach into the AI TAM, which remains underappreciated in current street estimates.

Author
Conclusion
Despite the ongoing threat of competition, especially given rapidly evolving innovation dynamics, AMD’s roadmap laid out during the Advancing AI keynote continues to reinforce confidence in its longer-term revenue share gains. The end-to-end AI infrastructure leadership that AMD demonstrates today – spanning data center CPUs and GPUs, networking and AI PCs; and from hardware to software to cluster level systems – makes it well-positioned for additive growth as industries onboard a “once in 50 years type computing super cycle”.
We believe the Advancing AI keynote sets a strong tone for AMD’s upcoming earnings release, as next-generation products underpin further growth and margin accretion. The upcoming start of volume production for MI325X accelerators and EPYC Turin server processors should reinforce an accelerating growth trajectory in data center sales, despite heading into a tough PY compare set-up that laps the MI300’s debut. This is expected to drive an uplift to AMD’s growth outlook and underpin an upward re-rate to its valuation from current levels.
Editor’s Note: This article discusses one or more securities that do not trade on a major U.S. exchange. Please be aware of the risks associated with these stocks.
Analyst’s Disclosure: I/we have no stock, option or similar derivative position in any of the companies mentioned, and no plans to initiate any such positions within the next 72 hours. I wrote this article myself, and it expresses my own opinions. I am not receiving compensation for it (other than from Seeking Alpha). I have no business relationship with any company whose stock is mentioned in this article.
Seeking Alpha’s Disclosure: Past performance is no guarantee of future results. No recommendation or advice is being given as to whether any investment is suitable for a particular investor. Any views or opinions expressed above may not reflect those of Seeking Alpha as a whole. Seeking Alpha is not a licensed securities dealer, broker or US investment adviser or investment bank. Our analysts are third party authors that include both professional investors and individual investors who may not be licensed or certified by any institute or regulatory body.