
Summary:
- Nvidia’s expensive GPUs are dominating the data center hardware market, displacing CPU compute and cutting into customer margin.
- Google is the one big exception, using their own custom silicon, the TPU. They also rent them out at Google Cloud, alongside Nvidia hardware. They just introduced version 5e.
- TPU chips are made by Broadcom and TSM. But this boost from Google is not enough to make up for weakness elsewhere for Broadcom.
- I am keeping a close eye on TPU and Broadcom, but remain on the sidelines.
Justin Sullivan
Nvidia Is Taking (Almost) All The Money
Since the spring, I have been repeating a phrase about data center hardware: Nvidia is taking all the money. For the price of a GPU server, you can buy 10 or more CPU servers, and 90% of a GPU server goes to Nvidia. Very high cost GPUs from Nvidia are cannibalizing other data center hardware.
Nvidia is a month behind in their reporting. (Quarterly reports for NVDA, INTC and AMD)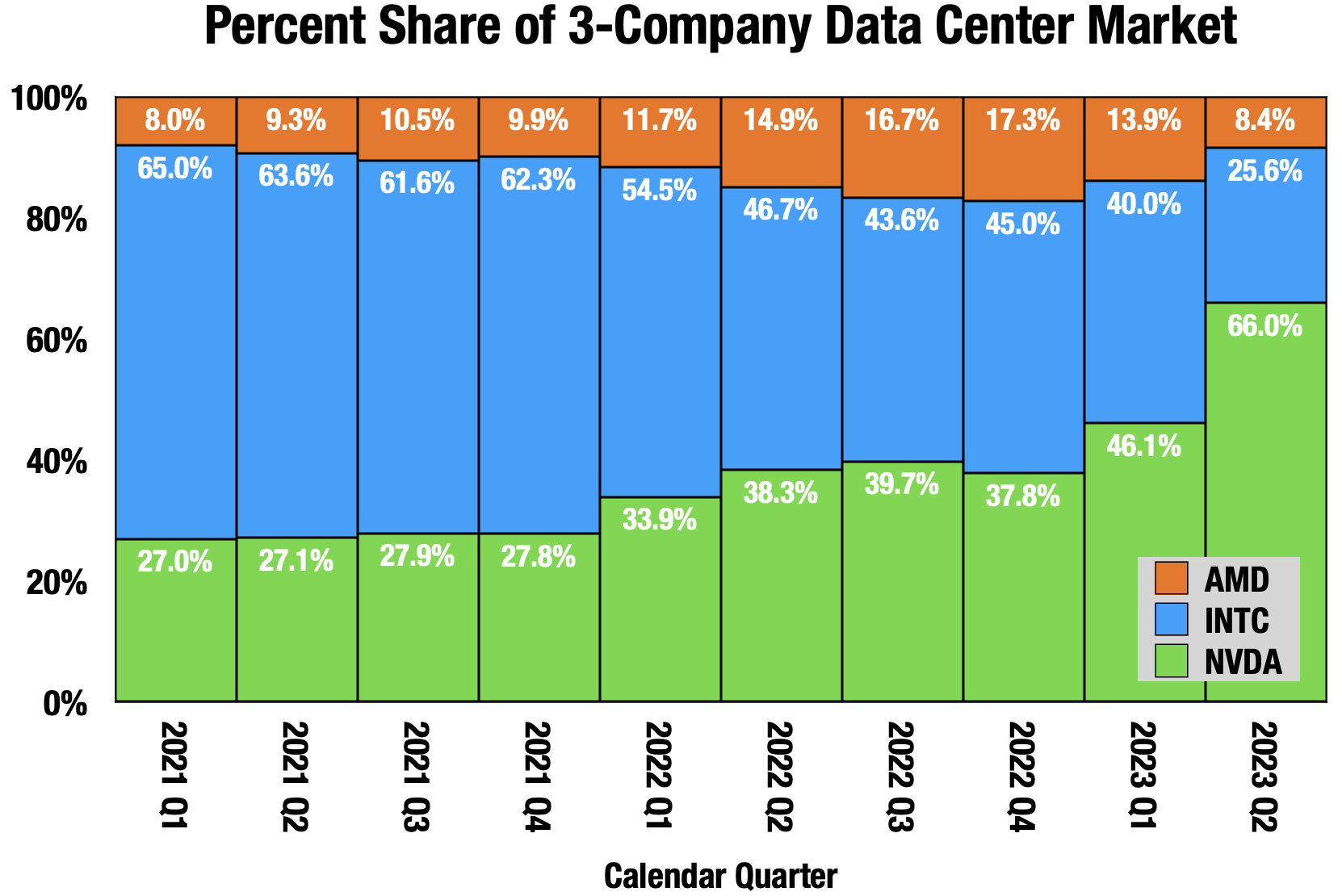
Intel (INTC) got the contract for Nvidia’s GPU server, the DGX-H100. It comes with two of Intel’s most expensive CPUs, and that hasn’t done much to help Intel. Nvidia is even stealing margin from their customers.
AMZN quarterly earnings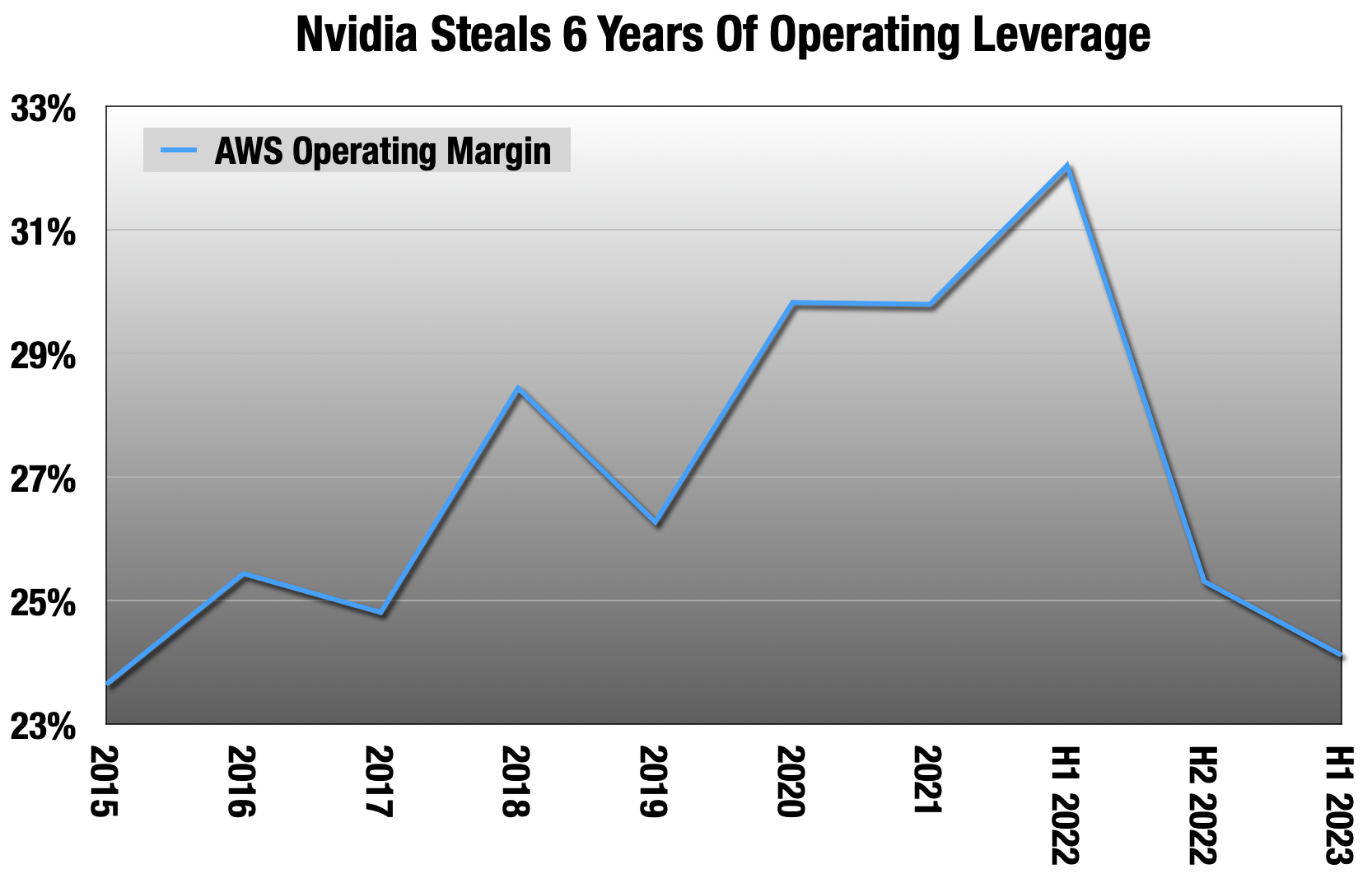
It took AWS (AMZN) six years to get their operating margin to 32% from 24%, and a year for Nvidia to wipe that out.
But among the big AI players, Google and Google Cloud (NASDAQ:GOOG), (NASDAQ:GOOGL) is sort of an exception. Like their competitors, they want as many Nvidia H100 GPUs to rent out as they can get their hands on. But Google also has the Tensor Processing Unit, the TPU. This is an “AI accelerator”: non-GPU hardware that is specialized for matrix multiplication, the main thing that makes AI GPU compute so expensive. A few weeks ago, along with their new Nvidia H100 GPU cloud instances, Google also announced TPU version 5e, in preview.
The TPUs are designed by Broadcom (NASDAQ:AVGO) and manufactured by Taiwan Semiconductor (TSM).
TPU v5e (the “e” is for “efficiency”)
A TPU v5e “pod” with 256 TPU chips in it. For comparison, the Nvidia pod has 128 GPUs. It looks like Intel got the CPU contract, like they did with Nvidia (Google Cloud)
In the mid-twenty-teens, Google had large AI ambitions. They still do, and around 2015 they had the same problem everyone has today: Nvidia GPUs were expensive to buy and deploy at scale, and hard to find in the large quantities they needed. So they decided to make their own custom silicon, the TPU. Like most of its successors in the AI accelerator space, it is a workaround to the computationally expensive floating point matrix multiplication math that GPUs are so good at. It trades off lower levels of precision for decreased cost. There is a large body of research that shows that the very high levels of precision you get with GPUs are wasted on most applications. All Google AI services, which extend across everything – Search, ads, Maps, YouTube, etc. – run on TPU, a big cost advantage to them
You will sometimes see these referred to as ASICs – application-specific integrated circuits – which is a general name for chips designed to do one thing very well. I prefer “AI accelerator” just for specificity.
TPU v1 came out in 2016, and was only for internal use. TPU versions 2-4 are also all available on Google Cloud, and they are now being joined by v5e. Version 5, beefier and less efficient, remains unannounced. Versions 1 through 4 were designed around Google’s internal needs, but it looks to me like they designed v5e with cloud customers in mind.
TPUs are slower than GPUs per chip, but also far cheaper to buy and run at scale. So the key is throwing many of them at a task. While TPU v4 maxed out at 4k chips, 5e will be “tens of thousands.” You can rent out the whole data center. This will allow for much larger models to be trained and deployed on TPU than before. They say up to two trillion parameters, which I think would support GPT-4.
Per chip, it sounds to me like the performance you get from v5e is about the same as v4 or even worse, depending on the workload. But it is far more inexpensive and efficient, so they are charging 63% less per chip to rent, so the same job would see a similar cost savings over v4.
TPU v5e versus TPU v4 (Google Cloud)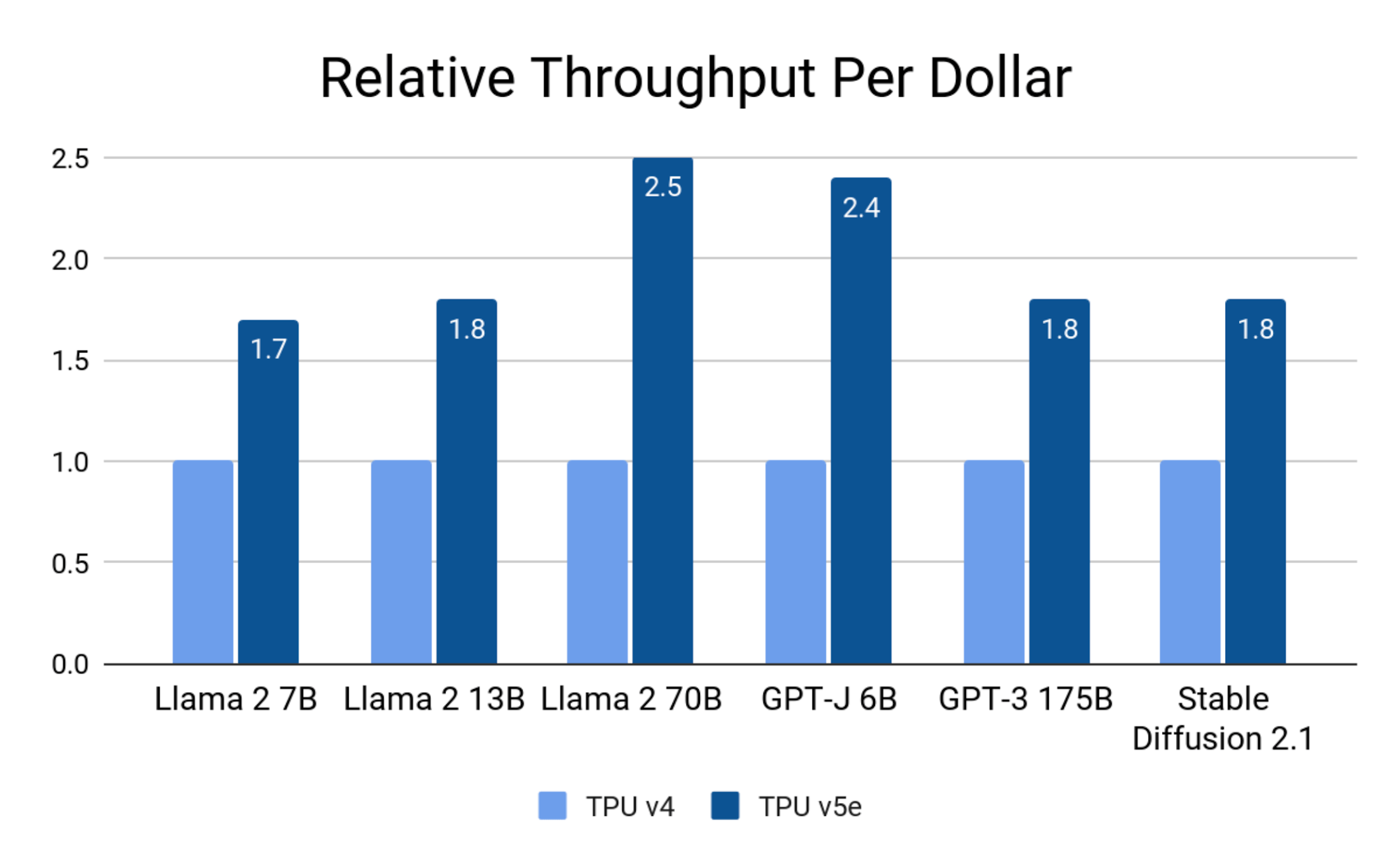
We only have good comparisons between the previous generations from both Google and Nvidia, TPU v4 and Nvidia A100. But based on a lot of extrapolation, my best guess is that TPU v5e will bring something like 40-70% cost savings to customers over Nvidia H100 for the same job on Google Cloud, even better than the previous generations. The big difference now is that TPU can handle much larger models than before. These TPUs are a big cost advantage to Google internally for their own extensive AI work.
But software is Nvidia’s moat, not hardware. There are a lot of AI accelerators out there now, and more coming, that can do this sort of work for far less than Nvidia GPUs. But Nvidia has been building software tools to train models and run them in production since 2005, and they have a high stack that keeps growing.
One key thing with the TPU v5e release is that they followed AWS’s lead and integrated popular open source AI frameworks as services. But they need to do more to match that Nvidia stack if they want to drain that moat.
Google very obviously focused first on costs when designing the v5e pods and how they connect. One advantage they have over Nvidia is that they have always been designing these things with the pods and entire data centers in mind, whereas Nvidia is new to that. This video shows the new TPU v5e data center.
From the satellite image in the video, it looks like it is near Columbus, Ohio. My best guess from looking at it is that there are about 128 pods in that data center, meaning 33k chips total. You can rent out that entire data center for one job, and run it in parallel.
A lot of what you see there – the chips, the internal networking “fabric” within the pods, and all that networking hardware outside the pods, comes from Broadcom.
Broadcom
If this stuff was all Broadcom made – those TPU chips and all the very high-end networking surrounding it – they would be sitting pretty, growing in the mid-20s. But they make a lot of other stuff, much of it for weak smartphone and PC markets.
They said that absent AI, the rest of their semiconductor segment is flat YoY. Overall, it is growing in mid-single digits. They are guiding to that same dynamic next quarter – big surge from AI, but everything else flat.
Through several acquisitions, they now also have a large software segment, and it may get larger with the addition of VMWare (VMW), pending approval in October. I expect they will get it, and add to this:
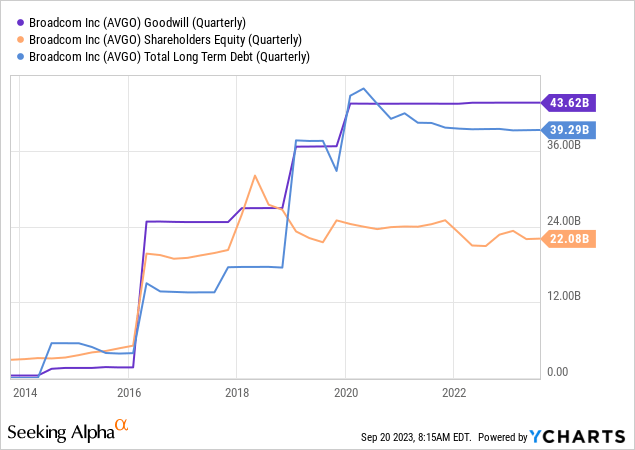
61% of their assets are goodwill, now $22 billion more than shareholder equity. Without goodwill, they would have -$22 billion in shareholder equity. The debt you see, and they will be adding to debt and goodwill with this acquisition.
Besides the balance sheet issues it brought, the software segment is also growing at mid-single digits, and guidance is for more of the same.
Broadcom is in better shape than other data center competitors because of their relationship with Google and the software segment, less cyclical than hardware. They had been forecasting a “soft landing,” and they got that. Compared to networking competitor, Marvell (MRVL):
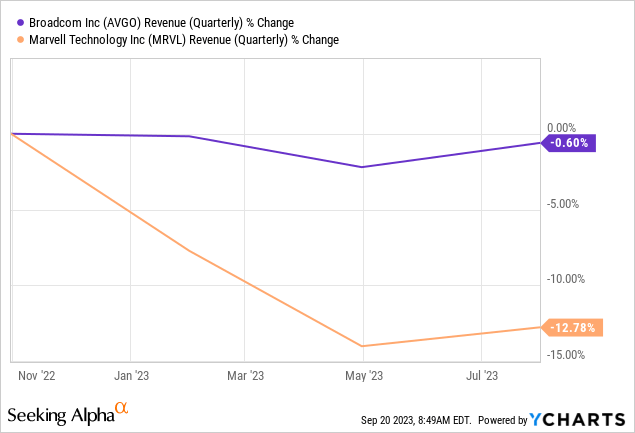
In their guidance, we see more of the same next quarter for both of these companies. Not much to get excited about. The sales to that Google data center seen in the YouTube video were baked into Broadcom’s reported quarter and guidance. It is a tailwind, but not yet big enough to make up for other slowness.
Broadcom has a lot riding on Google. They are also the contract for the unannounced TPU v5 hardware, may be building out right now. The real upside potential for both is if TPU can catch on and start displacing GPU compute. It is an uphill battle because of Nvidia’s software moat.
The Upshot
For now, I’m sitting on the sidelines with both these companies. I was already watching Google Cloud and TPU very closely, but v5e has even more potential to disrupt Nvidia. Like AWS’s AI infrastructure, they come with popular open source software tools ready to go as services. But that’s not enough. Bringing a software stack to match Nvidia’s is the key here. But if they can gain traction, it will also be a big tailwind for Broadcom
Analyst’s Disclosure: I/we have a beneficial long position in the shares of TSM either through stock ownership, options, or other derivatives. I wrote this article myself, and it expresses my own opinions. I am not receiving compensation for it (other than from Seeking Alpha). I have no business relationship with any company whose stock is mentioned in this article.
Seeking Alpha’s Disclosure: Past performance is no guarantee of future results. No recommendation or advice is being given as to whether any investment is suitable for a particular investor. Any views or opinions expressed above may not reflect those of Seeking Alpha as a whole. Seeking Alpha is not a licensed securities dealer, broker or US investment adviser or investment bank. Our analysts are third party authors that include both professional investors and individual investors who may not be licensed or certified by any institute or regulatory body.
20% OFF! Until the end of September, annual subscriptions will come with a 20% discount for the first year.
At Long View Capital we follow the trends that are forging the future of business and society, and how investors can take advantage of those trends. Long View Capital provides deep dives written in plain English, looking into the most important issues in tech, regulation, and macroeconomics, with targeted portfolios to inform investor decision-making.
Risk is a fact of life, but not here. You can try Long View Capital free for two weeks.
