
Summary:
- Nvidia Corporation, developed a first-mover advantage in AI cloud computing that consists of reinforcing layers and is very much a moving target.
- We don’t see any of the established big players like Microsoft or Google making much of a dent, most produce chips for use in their own cloud.
- AMD should gain a single-digit share as Nvidia chips are in short supply and AMD chips offer solid performance.
- Longer term, software trends towards more interoperability/portability and upstarts with ground-up approaches offering order of magnitude improvements could start to gain traction.
Noah Berger
Nvidia Corporation (NASDAQ:NVDA) is the 800-pound gorilla in the artificial intelligence (“AI”) training and inference market in the cloud. The company has been very forward-looking, leveraging its advantage in GPUs with network and software layers creating a first-mover advantage and network effects that make its position very difficult to unseat.
Nvidia’s chips (A100, H100, H200, and the upcoming Blackwell chips that have just been announced) compete with a chip, namely the Advanced Micro Devices (AMD) MI300X, that might beat some of its present chips in raw performance. This chip, however, isn’t going to cut it as an Nvidia-killer, even if AMD’s chip is likely to gain some market share simply due to the shortage in Nvidia’s chips.
Other big cloud players like Google, Microsoft, Meta, Alibaba, and IBM have come up with their own chips, but these are for internal use, they’re not selling them to third parties.
It might seem that Nvidia’s position is unassailable, yet there are two reasons why we think that over time, it can be eroded:
- GPUs are not designed for AI originally, while Nvidia is addressing this shortcoming with every new generation of AI chip (like the latest Blackwell ones introduced this week), but a ground-up design from scratch has the potential to offer something dramatically better. We’ll identify at least two promising candidates below.
- Open source software and interoperability solutions can undermine an important layer of Nvidia’s competitive advantage, its proprietary CUDA software layer that has been optimized for its chips and has a huge library and user basis. We’ll discuss some of these developments.
Combining the two reinforces the competitive threat, as greater interoperability or portability of software lowers the barriers to using different chips, which becomes especially enticing if these offer significant advantages (in terms of speed, price, energy use, etc.).
While we think that Nvidia has very little to fear from the established names, the combination of these software developments and the arrival of some new exciting solutions engineered from the ground up for large AI models by upstarts like Cerebras and SambaNova have the potential to gain traction.
That doesn’t make Nvidia a bad investment, there is a huge shortage in the market, which is still growing very fast and Nvidia is likely to remain the dominant player for some time to come.
We should also not forget that Nvidia itself is very much a moving target, as we were reminded of this week.
But we have to say, we found some of these upstarts, especially the two we just mentioned, offering intriguing possibilities. The evolution towards more interoperable and/or portable software could be a tailwind for newcomers.
A step change in demand
LLMs (Large Language Models) are very large indeed (and there is a more or less linear relation between the size and quality of the output). A LLM like GPT-4 consists of some 100T parameters amounting to roughly 400TB of model data, with petabytes of training data moving in and out of the model repeatedly.
A single chip simply doesn’t cut it (unless it’s one of Cerebras, see below), in order to train a LLM, one has to have a server rack stacking 8 Nvidia H100 GPUs connected to every other GPU (complemented by 4 NV Switches connecting the GPUs and 2 Intel CPUs).
But even a single server rack doesn’t get you very far:
The most popular deep learning workload of late is ChatGPT, in beta from Open.AI, which was trained on Nvidia GPUs. According to UBS analyst Timothy Arcuri, ChatGPT used 10,000 Nvidia GPUs to train the model.
“But the system is now experiencing outages following an explosion in usage and numerous users concurrently inferencing the model, suggesting that this is clearly not enough capacity,” Arcuri wrote in a Jan. 16 note to investors.
According to Semianalysis:
OpenAI requires ~3,617 HGX A100 servers (28,936 GPUs) to serve Chat GPT.
This looks like inference, which is less compute-hungry as the parameters are static. As LLMs get into ever more applications, and the speed of this surprised Morgan Stanley analyst Joseph Moore, it’s resulting in a tremendous growth for Nvidia GPUs and (Super Micro) server racks alike, the data center has become the new unit of compute.
Competitive advantage
Training LLMs requires unprecedented memory and parallel compute power, Nvidia was lucky enough to have the best GPU around in 2017:
when Google introduced the “transformer” model on which most generative AI is now based, AI researchers realized that they needed the parallel processing capabilities offered by GPUs. At which point it became clear that Nvidia was the outfit that had the head start on everyone else.
So they could transfer the domination in gaming to AI, but for those that wait for competitive GPUs to take on Nvidia’s A100 and H100 chips, it’s not as simple as that, far from it.
There are basically three areas relevant for training and running LLMs, and Nvidia is dominant in all three:
- Hardware: GPUs and accelerators
- Networking
- Software: CUDA.
Competition in AI chips
Two powerful forces are driving increasing competition:
- The scarcity of AI chips
- The tremendous amount of money to be made if one can do it at scale.
There is already a lot of competition:
Google (GOOG) (GOOGL) with Tensor, which it argued outperforms Nvidia’s A100 in a system with 4000 of its tensor chips (compared to a similar configuration with A100 chips). The advantage doesn’t actually originate in faster processing, but in the optical switching tech between the chips.
Nvidia isn’t too worried, as the H100 is 9x faster than the A100 (and the H200 is faster still), and the fact that Google isn’t competing with Nvidia as it isn’t selling the chips to others (it’s using them in its own data centers) tells quite a lot.
Microsoft (MSFT) with Maia offers another alternative introduced late last year:
Manufactured on a 5-nanometer TSMC process, Maia has 105 billion transistors — around 30 percent fewer than the 153 billion found on AMD’s own Nvidia competitor, the MI300X AI GPU. “Maia supports our first implementation of the sub 8-bit data types, MX data types, in order to co-design hardware and software,” says Borkar. “This helps us support faster model training and inference times.”
But this too doesn’t seem to be intended to compete head-on with Nvidia:
Along with sharing MX data types, Microsoft is also sharing its rack designs with its partners so they can use them on systems with other silicon inside. But the Maia chip designs won’t be shared more broadly, Microsoft is keeping those in-house… That makes it difficult to decipher exactly how Maia will compare to Nvidia’s popular H100 GPU, the recently announced H200, or even AMD’s latest MI300X. Borkar didn’t want to discuss comparisons, instead reiterating that partnerships with Nvidia and AMD are still very key for the future of Azure’s AI cloud.
It does offer a replacement to run in part of its own cloud to lessen its dependence on Nvidia and the shortage of its chips. As it happens, it seems more of a competing solution for Super Micro (SMCI) servers, taking on its liquid cooling solution:
“Maia is the first complete liquid cooled server processor built by Microsoft,” reveals Borkar. “The goal here was to enable higher density of servers at higher efficiencies. Because we’re reimagining the entire stack we purposely think through every layer, so these systems are actually going to fit in our current data center footprint.”
Amazon’s (AMZN) Trainium (now in its second generation) is also for internal use.
Intel’s (INTC) Gaudi 2 accelerator was 55% faster in a benchmark test with the A100 and H100 in training even if Nvidia’s chips perform better at inferencing, and Intel’s upcoming Gaudi 3 should be better still, but Intel’s strength is in CPU’s, not GPUs and they have a better opportunity in the edge-inference market (most notably PCs of course).
AMD especially seems to offer some serious competition with the MI300X outperforming Nvidia’s H100:
AMD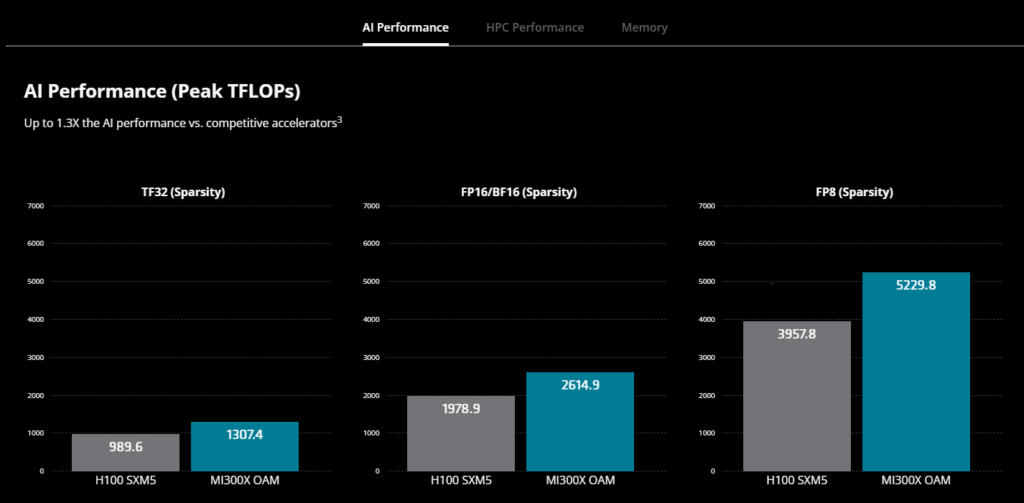
But Nvidia already has the H200 and now the upcoming Blackwell, but even against these AMD seems to more than hold its own (Techwire Asia):
MI300X GPU will still have more memory bandwidth and memory capacity than Nvidia’s next-generation H200 GPU
There are recent reports that the MI300X could attain a 7% market share, mostly due to the supply limitations of Nvidia chips, but a better price/performance ratio is also a factor.
Upstarts
Then there are accelerator startups that design ‘pure’ AI chips unconstrained from the general GPU demands and can optimize for machine learning alone.
Probably the biggest GPU limitation is what’s called the Memory Wall, with AI chips spending much if not most of the time shuffling data in and out of memory, given the huge and increasing size of data involved in training and running large AI models.
This slows things down as separate memory chips have to be addressed and these connections are orders of magnitude slower than those on a die.
On the one hand the Memory Wall is getting more serious as the compute power has advanced much more rapidly compared to memory:
Comparing Nvidia’s 2016 P100 GPU to their 2022 H100 GPU that is just starting to ship, there is a 5x increase in memory capacity (16GB -> 80GB) but a 46x increase in FP16 performance (21.2 TFLOPS -> 989.5 TFLOPS).
This is only somewhat mitigated by the fact that as large AI models get bigger, their demands on compute power increase relative to their memory demands.
Our first two upstarts (Cerebras and SambaNova) offer unique ways to break down the Memory Wall:
Cerebras has developed a wafer-sized AI chip in order to overcome the memory wall by doing everything on a single die, building a giant chip. The promise for their recently launched third iteration is substantial (emphasis added):
With a huge memory system of up to 1.2 petabytes, the CS-3 is designed to train next generation frontier models 10x larger than GPT-4 and Gemini. 24 trillion parameter models can be stored in a single logical memory space without partitioning or refactoring, dramatically simplifying training workflow and accelerating developer productivity. Training a one-trillion parameter model on the CS-3 is as straightforward as training a one billion parameter model on GPUs.
Training an AI model 10x the size of GPT-4 on a single chip (even if it’s as large as a wafer) is pretty impressive stuff. The leading idea is to reduce the training of AI models from weeks to hours.
It achieves that because everything is on the silicon, all the memory as well, rather than having to dig into other chips (like memory), and this improves bandwidth by up by four orders of magnitude. There is clever software as well that keeps the chip running smoothly.
And since there are thousands of cores, the chip can have up to 1% of redundant one to absorb the inevitable faults during production. Producing the chip requires quite a bit of customization, but it turned out to be doable.
It already has a previous generation system in a data center in Dubai and at Arbonne National Laboratory and there is a considerable backlog, the demand is emerging.
One might notice that by keeping all the memory on the same die Cerebras effectively neutralizes Nvidia’s advantage in networking as well (see below), in fact, it’s the core of Cerebras’ approach.
SambaNova first came with its own AI chip, the SN40L, which it doesn’t sell but instead put into its AI platform which can be installed on-premise and is also offered to businesses as an AI platform as a service.
It doesn’t sell separate AI chips because it offers a whole new architecture in the form of what it calls RDA (Reconfigurable Dataflow Architecture), liberating AI from the constraints of traditional software and hardware.
They offer software-defined AI hardware that overcomes the huge demands on memory It’s explained in some detail here:
It may seem obvious, but it needs to be said that as LLMs continue to get bigger, they will take up more space in memory. This is important to this discussion because when an AI model is given a prompt, the entire model is loaded into on-chip memory. All possible results are calculated, and then the model determines the most correct response and returns that as the result. The model is then written from on-chip memory back to system memory. This process happens every time that a prompt is given to the AI model.
To be able to process this requires that either the processor being used have sufficient memory to hold the entire model or be configured in such a way that the model is broken into parts and then spread across however many processors are needed to run the model. Clearly, if the model is being spread across multiple nodes, then there is configuration and management overhead required to parallelize the nodes, manage the model, and so forth.
Given that models have now reached a trillion parameters in size and are continuing to grow rapidly, this presents a major hurdle to GPUs. Nvidia GPUs, such as the A100 and H100, have 80GB of on-chip memory, which is only a small fraction of what is required for modern generative AI models. As a result, running these models on Nvidia GPUs can require a huge number of systems, along with all the associated costs and overhead. While this may be great for Nvidia’s bottomline, it can be a massive expense and technical challenge for the end customer.
In contrast, the SambaNova SN40L has a three tiered memory architecture, specifically designed for the largest generative AI models. The SN40L has terabytes of addressable memory and can easily run trillion parameter models on a single SambaNova Suite node.
We had to quote at length because it describes the limitations of the GPU-based architecture (and how Nvidia is printing money from it, as ever-larger LLMs dramatically escalate the need for additional nodes) very well.
Simply put, one could argue that what Cerebras does in silicon, SambaNova tries to do in software, that is, overcoming the memory wall (the fact that most of the time the chips are waiting to get data in and out of memory).
Management is nothing short of ambitious (our emphasis):
This concept of dataflow is central to SambaNova’s notion of how next generation computer architectures will operate, and it is such a step change that the company believes it will usher in a new era of computing.
The White Paper from which this quote comes goes on to explain their new architecture. Its system has been put into practice at the Lawrence Livermore National Laboratory:
Researchers have already reported that the DataScale system demonstrates a five times improvement over a comparable GPU running the same models. SambaNova said a single DataScale SN10-8R can train terabyte-sized models, which would otherwise need eight racks worth of Nvidia DGX A100 systems based on GPUs.
We think they are onto something, and so do a host of venture capitalists:
AIMultiple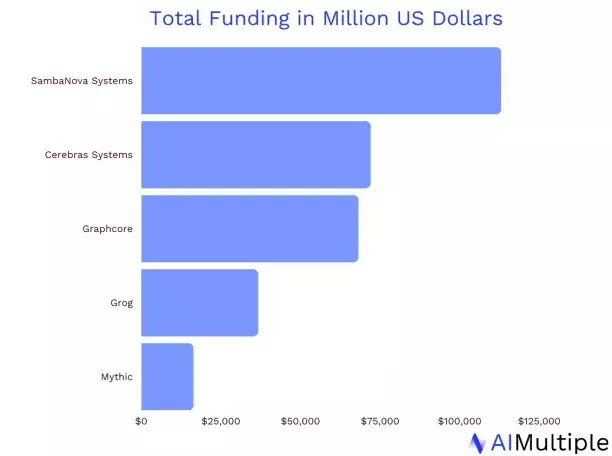
Groq has developed a very fast LPU (Language Processing Units) which does inference very well, (even setting records) which is an easier market to get into but it’s not a training solution and it’s more of an edge solution. But Groq isn’t there yet:
Comparing the Groq LPU card to NVIDIA’s flagship A100 GPU of similar cost, the Groq card is superior in tasks where speed and efficiency in processing large volumes of simpler data (INT8) are critical, even when the A100 uses advanced techniques to boost its performance. However, when handling more complex data processing tasks (FP16), which require greater precision, the Groq LPU doesn’t reach the performance levels of the A100.
Essentially, both components excel in different aspects of AI and ML computations, with the Groq LPU card being exceptionally competitive in running LLMS at speed while the A100 leads elsewhere. Groq is positioning the LPU as a tool for running LLMs rather than raw compute or fine-tuning models.
Graphcore has built a promising 3-D AI chip with two dies stacked on top of one another (a bit like NAND chips) which is capable of 350T floating point per second of mixed-precision AI arithmetic, which makes it the fastest AI chip in the world bar the Cerebras WSE-2 chip. Graphcore announced that its
updated models of its multi-processor computers, called “IPU-POD,” running the Bow chip, which it claims are five times faster than comparable DGX machines from Nvidia at half the price
But its CEO argues that software is actually more important, and he might be onto something.
Esperanto has developed an inference RISC-V based chip, the ET-SOC-1 AI for data centers (but it also comes in an PCIe card) that is very energy efficient. A second generation of the chip is already underway.
Syntiant has a portfolio of Neural Decision Processors which are efficient edge inference solutions but for specific AI applications (analyzing sensor, audio and computer vision data).
EnCharge AI is working on an innovative inference edge solution that promises to drastically slash energy needs of running LLMs for inference. The key is reducing the tremendous energy needs created by memory access:
The key insight by Verma and other pioneers of IMC research is that AI programs are dominated by a couple of basic operations that draw on memory. Solve those memory-intense tasks, and the entire AI task can be made more efficient
EnCharge solves this with the help of a dual digital/analog chip with the energy-efficient analog part taking on the heavy-duty memory-intensive workload, but this is also a solution for edge inference, not training LLMs in data centers.
Korea Advanced Institute of Science and Technology (KAIST)
Something from outer left field is the announcement by KAIST of its upcoming “Complementary-Transformer” AI chip, which:
claiming that the C-Transformer uses 625 times less power and is 41x smaller than the green team’s A100 Tensor Core GPU. It also reveals that the Samsung fabbed chip’s achievements largely stem from refined neuromorphic computing technology.
This stretches the belief of many as the chip was fabricated at 28nm and there is no independent benchmark, but KAIST is a serious institution, and the explanation for this, at face value miraculous performance derives from enlisting neuromorphic computer technology for LLMs:
Previously, neuromorphic computing technology wasn’t accurate enough for use with LLMs, says the KAIST press release. However, the research team says it “succeeded in improving the accuracy of the technology to match that of [deep neural networks] DNNs.”
This too is an edge/inference chip. Nevertheless, a promising one on paper, it will be interesting to see what, say, a 4nm version of the chip can do.
Then there is of course a separate race for Edge AI chips like those running PCs, with Intel, AMD, Qualcomm, Google, and Apple in the mix but this isn’t eating Nvidia’s cloud dominance away.
Networking
That networking is very important should have been obvious from the first part of this article, given that no single GPU, nor a single server, not even a single server rack is anywhere close to enough to train and run LLMs, it takes massive computing power running in parallel to accomplish that.
This means that the speed, bandwidth and latency of connections between the chips (very much including memory, an important bottleneck) are crucial variables.
Nextplatform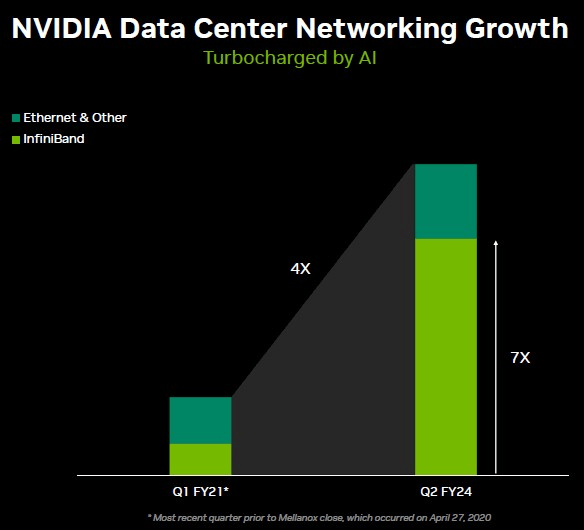
These chips have to be connected and connected at speed, tremendous capacity and with near zero latency.
It’s here, too, that Nvidia has advantages, which it is taking a step further with the Blackwell announcements (our emphasis):
NVIDIA today announced a new wave of networking switches, the X800 series, designed for massive-scale AI. The world’s first networking platforms capable of end-to-end 800 Gb/s throughput, NVIDIA Quantum-X800 InfiniBand and NVIDIA Spectrum -X800 Ethernet push the boundaries of networking performance for computing and AI workloads… The Quantum-X800 platform sets a new standard in delivering the highest performance for AI-dedicated Infrastructure. It includes the NVIDIA Quantum Q3400 switch and the NVIDIA ConnectX -8 SuperNIC, which together achieve an industry-leading end-to-end throughput of 800G b/s. This is 5x higher bandwidth capacity and a 9x increase of 14.4 Tflops of In-Network Computing with NVIDIA’s Scalable Hierarchical Aggregation and Reduction Protocol (SHARPv4) compared to the previous generation.
To give you an idea of the problem these are trying to reduce:
Previously, Nvidia says, a cluster of just 16 GPUs would spend 60 percent of their time communicating with one another and only 40 percent actually computing.
The company also introduced the next-generation NVLink switch, which:
Lets 576 GPUs talk to each other, with 1.8 terabytes per second of bidirectional bandwidth. That required Nvidia to build an entire new network switch chip, one with 50 billion transistors and some of its own onboard compute: 3.6 teraflops of FP8, says Nvidia.
CUDA
A third area of competitive advantage for Nvidia lies in its CUDA (Compute Unified Device Architecture), which enabled developers to leverage the enormous parallel processing power of its chips.
Since CUDA predates generative AI the company had a double first-mover advantage, not only having the best graphics chips for the huge amount of processing power necessary, but also the best programming platform in CUDA.
It’s crucial to understand that this double first-mover advantage reinforced itself to create something of a virtuous cycle, which Nvidia actively reinforced:
CUDA was developed from ground up to be accessible to a broad audience of developers. Nvidia invested heavily in libraries like cuDNN for deep learning, cuBLAS for linear algebra, cuFFT for FFTs etc. to accelerate different domains. The proprietary nature of CUDA allowed Nvidia to continuously optimize it over the years for its evolving GPU architectures without sharing insights with competitors. This resulted in CUDA applications seeing much better performance and efficiency gains on Nvidia hardware compared to vendor-neutral solutions like OpenCL.
Since its chips were the best customers adopted them and since CUDA was the natural platform for working with the chips, they adopted that too, creating widespread adoption which produced a network effect and making it hard for competitors to match.
Alternative platforms (AMD’s MIOpen and Intel’s oneAPI) have come to little as they suffer from a chicken and egg problem, a limited base creates insufficient incentives to close the gaps in tools and libraries on CUDA, which keeps the base limited.
Nvidia can’t rest on its laurels, given the tremendous monetary incentives to eat into its huge chunk of the generative AI market spoils, and the scarcity of its chips, which produces big incentives to look for alternative platforms.
Nvidia keeps rapidly adding CUDA capabilities and libraries, collaborating with researchers and organizations, and integrating with all major deep learning frameworks and the like.
One point of attack is the difficulty of porting complex neural network codebases from CUDA to different programming platforms, as companies are working on Open systems and interoperability solutions. There is for instance the Open Compute Project:
Microsoft is part of a group that includes AMD, Arm, Intel, Meta, Nvidia, and Qualcomm that are standardizing the next generation of data formats for AI models. Microsoft is building on the collaborative and open work of the
Open Compute Project (OCP) to adapt entire systems to the needs of AI.
There are many other initiatives here, from PyTorch, ROCm, Triton, oneAPI, Lambda Labs, JAX, Julia, cloud-based abstraction layers like Microsoft Cognitive Toolkit, ONNX Runtime and WinML, and more that each addresses aspects and offers alternatives (the specifics go beyond the scope of this article).
The ones that seem most promising are PyTorch and Triton, as well as AMD’s ROCm. PyTorch initially helped Nvidia through operator fusion, which is a way to reduce the memory bandwidth bottleneck which PyTorch actually increased with its Eager mode (an alternative to the more complex Graph Mode):
When executing in Eager mode, each operation is read from memory, computed, then sent to memory before the next operation is handled. This significantly increases the memory bandwidth demands if heavy optimizations aren’t done. As such, one of the principal optimization methods for a model executed in Eager mode is called operator fusion. Instead of writing each intermediate result to memory, operations are fused, so multiple functions are computed in one pass to minimize memory reads/writes.
However:
Eager mode execution plus operator fusion means that software, techniques, and models that are developed are pushed to fit within the ratios of compute and memory that the current generation GPU has… The growth in operators and position as the default has helped Nvidia as each operator was quickly optimized for their architecture but not for any other hardware.
An obvious solution would be software that runs on Nvidia’s chips to transfer seamlessly to other hardware, PyTorch 2.0 is addressing this, in two ways:
- Adding a compiled solution that supports a graph execution model (rather than the Eager mode in which it normally runs), making utilizing different chips much easier.
- Simplifying graph mode through TorchDynamo.
- Reducing the number of operators from 2K+ to some 250 with PrimTorch, which makes the implementation of different, non-Nvidia backends to PyTorch much simpler (this is in Eager mode).
- TorchInductor, a python native deep learning compiler that generates fast code for multiple accelerators and backends which greatly reduces the work that goes into compilers for different AI accelerators (as well as reducing memory bandwidth and capacity requirements).
The latter is especially significant in combination with Open AI Triton (emphasis added):
Triton takes in Python directly or feeds through the PyTorch Inductor stack. The latter will be the most common use case. Triton then converts the input to an LLVM intermediate representation and then generates code. In the case of Nvidia GPUs, it directly generates PTX code, skipping Nvidia’s closed-source CUDA libraries, such as cuBLAS, in favor of open-source libraries, such as cutlass… Nvidia’s colossal software organization lacked the foresight to take their massive advantage in ML hardware and software and become the default compiler for machine learning. Their lack of focus on usability is what enabled outsiders at OpenAI and Meta to create a software stack that is portable to other hardware. Why aren’t they the one building a « simplified » CUDA like Triton for ML researchers?
So, it could be that Nvidia dropped the ball here to some degree and opened the door to software being portable to alternative accelerators.
At present, this matters less given its installed base and other advantages (most notably in the accelerators themselves), but it has opened the door for alternatives and given the scarcity of the Nvidia chips this is lowering the threshold for using alternatives.
Most notably those of AMD with its more open CUDA alternative ROCm. However, adoption is dependent on adoption of AMD chips (the MI300X).
Since the MI300X has a much smaller installed base it creates little reason for adopting ROCm or writing solutions for it, the familiar chicken and egg problem. Indeed:
While AMD has absolutely made progress with ROCm, the platform remains far behind CUDA in critical aspects like documentation, performance and adoption. Realistically, AMD will struggle to achieve parity let alone surpass Nvidia given their massive head start. Nvidia invests billions in CUDA development and ecosystem expansion annually.
The best that one can say is that it does lower the barrier as it lowers vendor lock-in, but at the same time ROCm makes it easier to switch back to Nvidia chips, so what the net effect is remains to be seen, and not everybody has a first-grade experience with it.
The new Blackwell B200 GPU and GB200 superchip.
All these efforts are very laudable, but in the meantime Nvidia came up with its newest AI chip, the Blackwell B200 GPU, which is another leap forward. Nvidia is of course a very moving target, First, the advancement in training:
Training a 1.8 trillion parameter model would have previously taken 8,000 Hopper GPUs and 15 megawatts of power, Nvidia claims. Today, Nvidia’s CEO says 2,000 Blackwell GPUs can do it while consuming just four megawatts.
And the advancement in inference is considerably bigger still:
Also, it says, a GB200 that combines two of those GPUs with a single Grace CPU can offer 30 times the performance for LLM inference workloads while also potentially being substantially more efficient. It “reduces cost and energy consumption by up to 25x” over an H100, says Nvidia.
This is management talking, not independent tests but in any case demand is already lining up. We should also not escape the progress in networking:
A second key difference only comes when you link up huge numbers of these GPUs: a next-gen NVLink switch that lets 576 GPUs talk to each other, with 1.8 terabytes per second of bidirectional bandwidth. That required Nvidia to build an entire new network switch chip, one with 50 billion transistors and some of its own onboard compute: 3.6 teraflops of FP8, says Nvidia.
And the connections for large systems like
the DGX Superpod for DGX GB200, which combines eight systems in one for a total of 288 CPUs, 576 GPUs, 240TB of memory, and 11.5 exaflops of FP4 computing. Nvidia says its systems can scale to tens of thousands of the GB200 superchips, connected together with 800Gbps networking with its new Quantum-X800 InfiniBand (for up to 144 connections) or Spectrum-X800 ethernet (for up to 64 connections).
Risk
There are always risks, even for a company with a solidified position as Nvidia:
The main risk we can identify is faster adoption of one of the upstart solutions like Cerebras. That didn’t happen for its first two versions of its wafer chip, but the third generation which they just recently launched offers orders of magnitude performance improvements. It is likely to gain traction and the speed of that could surprise on the upside. The same can be said for SambaNova, or some other solution out of left field we’re not aware off.
A risk to the stock is its high valuation, it’s always possible that Nvidia produces a quarter that doesn’t quite live up to expectations, perhaps due to execution problems, supply chain shortages and the like.
The overall market also poses a risk to the stock. The market is due for a correction and as one of the undisputed market leaders of the rally Nvidia is unlikely to escape such a downturn, even if many investors (ourselves included) will take this as a good buying opportunity.
We don’t see much in terms of economic risks, cost-savings are as much a reason for adoption of AI as it is for driving new business models and additional services. We don’t think a recession will slow adoption down much, if at all.
Valuation
The shares are richly valued, but that’s to be expected for the so far undisputed leader of the main economy-wide trend: generative AI where it has captured a disproportionate part of the value creation.
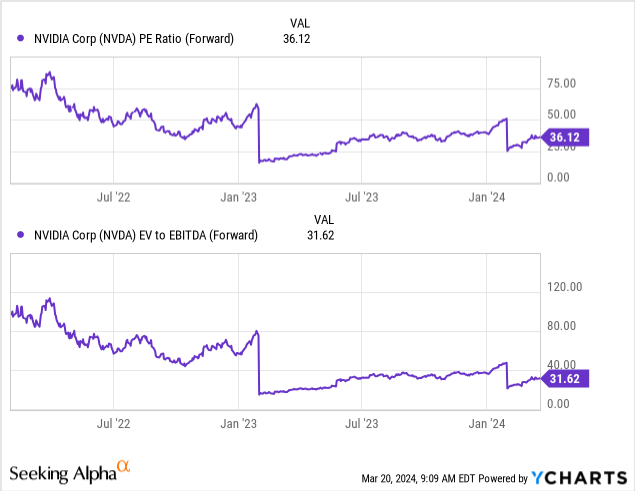
And we would argue that there is financial substance behind the valuation:
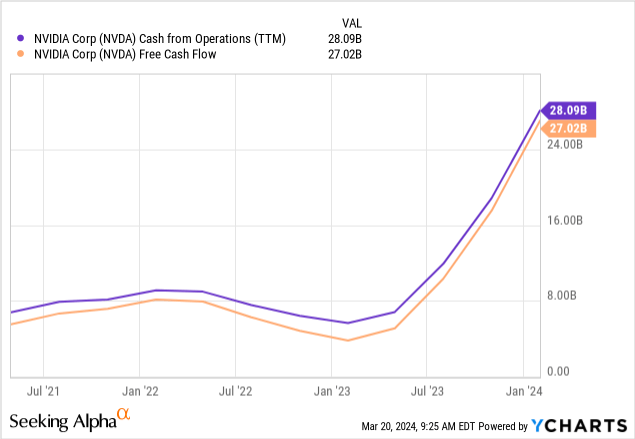
Conclusion
Nvidia Corporation’s dominant position isn’t dependent just on the quality of its GPUs, it’s a combination of GPU, network, and software solutions. To unseat Nvidia it has to be attacked and superseded on all three fronts at once, this is highly unlikely anytime soon, in our view.
Most big competitors in training chips seem to have developed these for use in their own cloud, like Microsoft and Google, to lessen their dependency on Nvidia (which they continue to use).
Some, in particular Intel and AMD, could very well gain some fractional market share, helped as much by the scarcity of Nvidia chips as their own improvements, if not more so. But we don’t see them giving Nvidia a run for its money anytime soon.
As GPUs weren’t originally designed for training LLMs, there is the possibility of radical improvement in chip design and some candidates seem to have embarked on a few promising approaches already. But to conquer the training market they also have to simultaneously offer solutions for networking and software, which makes the barrier that much higher.
The approaches to keep an eye on are from SambaNova and Cerebras. Both have ground-up system designs unincumbered by legacy limitations and they seem to produce order of magnitude improvements.
Efforts to make software more portable and/or interoperable seem to get some traction, which will lessen the stranglehold CUDA has on the software side and makes it easier to switch to another chip, at least in principle.
Many of the chips from upstarts target the less demanding inference edge market where they offer promising approaches that could supplement existing solutions from more established players like Qualcomm and Intel but Nvidia’s dominance is in the cloud, especially in training, so this isn’t a head-on competition with Nvidia.
The upshot is that we think Nvidia is relatively safe for some time to come. We see little in the way of a direct competitive threat that can seriously dent its dominant position anytime soon, but there are openings for interesting upstarts to gain a foothold in the market. So, we still rate Nvidia as a buy.
Analyst’s Disclosure: I/we have a beneficial long position in the shares of NVDA either through stock ownership, options, or other derivatives. I wrote this article myself, and it expresses my own opinions. I am not receiving compensation for it (other than from Seeking Alpha). I have no business relationship with any company whose stock is mentioned in this article.
Seeking Alpha’s Disclosure: Past performance is no guarantee of future results. No recommendation or advice is being given as to whether any investment is suitable for a particular investor. Any views or opinions expressed above may not reflect those of Seeking Alpha as a whole. Seeking Alpha is not a licensed securities dealer, broker or US investment adviser or investment bank. Our analysts are third party authors that include both professional investors and individual investors who may not be licensed or certified by any institute or regulatory body.
If you are interested in similarly small, high-growth potential stocks you could join us at our Full Service SHU Growth Portfolio, where we maintain a portfolio and a watchlist of similar stocks. Or you can choose the Basic Service which is a little more opportunistic and geared towards somewhat bigger stocks.
We add real-time buy and sell signals on these, as well as other trading opportunities that we provide in our active chat community. We look at companies with a defensible competitive advantage and the opportunity and/or business models that have the potential to generate considerable operational leverage.