
Summary:
- In Meta Platforms, Inc.’s latest earnings call, it played down its metaverse ambitions in favor of prioritizing AI investments across all arms of its business – particularly in its core advertising business.
- While Meta has long been alluding to AI as one of its core forward focus areas, it has also coincidentally paved way for its participation in the viral AI-chatbot sensation.
- The following analysis will zero in on LLaMA – the newest kid in town regarding conversational AI services – and gauge its impact on Meta’s forward fundamental and valuation prospects.
Kelly Sullivan
The viral sensation over chatbots following the public introduction of ChatGPT in December of last year has essentially kicked off an AI arms race across all corners of tech, both big and small. Companies like Google (GOOG / GOOGL), which were previously taking a conservative approach on the development and deployment of large language models (“LLMs”) similar to OpenAI’s GPT-3.5, which is behind ChatGPT, have in recent months rushed to showcase their strengths against incoming rivals (cue “Bard“). Meanwhile, Microsoft (MSFT) – a key backer of OpenAI – has been keen on capitalizing on its early investment by swiftly integrating the generative AI capabilities of ChatGPT into Bing – the online search engine most famously known as the lesser competition to Google, and ironically, the host to where “Google” is the number one search query.
In the generative AI landscape’s latest development is Meta Platforms, Inc.’s (NASDAQ:META) recent introduction of Large Language Model Meta AI, or “LLaMA.” The development complements Meta’s multi-quarter emphasis on bolstering its AI capabilities’ presence across all arms of its business, spanning social media advertising and ambitious metaverse aspirations that are still years from coming to fruition. LLaMA will mark Meta’s growing foray in the LLM arms race. Although the technology is not yet a direct revenue-generating segment for the company, we view it as crucial to putting Meta on the map among its big tech peers in the development and capitalization of growth opportunities in generative AI over the longer-term.
What is LLaMA?
Unlike ChatGPT or Bard, LLaMA is not a chatbot, but rather a compilation of LLMs similar to GPT-3.5 and LaMDA which are behind conversational AI applications. The goal that Meta has set out for LLaMA is to provide the required resources to help researchers make advancements to the nascent field of generative AI pertaining to conversational applications, including the need to address outstanding requirements over the safety, reliability, accuracy, and scalability of related technologies’ (e.g., AI-enabled chatbots) deployment. Essentially, LLaMA is currently a non-revenue-generating foray undertaken by Meta, and is not actively integrated into the company’s existing portfolio of businesses. LLaMA will be offered under a “non-commercial license” for research-focused use cases, applicable to users spanning “academic researchers; those affiliated with organizations in government, civil society, and academia; and industry research laboratories around the world.”
Compared to more well-known LLMs like OpenAI’s GPT-3.5 (up to 175 billion parameters), Google’s LaMDA (up to 137 billion parameters) and PaLM (540 billion parameters), and Microsoft’s Megatron-Turing Natural Language Generation model (530 billion parameters), Meta’s compilation of LLaMA models are significantly smaller in size. And the size of the model is important – a specific LLM’s parameter count essentially represents the volume of “nuances” that the model can process and understand for each word’s “meaning and context,” and is effectively a core driver of its performance.
LLaMA is currently available in four variants, spanning 7-billion, 13-billion, 33-billion and 65-billion parameters. Yet, even the smallest LLaMA-7B model has demonstrated capability in outperforming larger models like GPT-3.5 on most LLM-evaluating benchmarks, while the largest LLaMA-65b model have showcased competitive performance against some of the world’s largest and most powerful LLMs like DeepMind’s Chinchilla (70 billion parameters) and Google’s PaLM.
Understanding the Relationship Between Model Size and Data Input
So how exactly does LLaMA, which is significantly smaller in size compared to some of the world’s highest-performing LLMs, manage to stay just as – if not more – competitive?
While a larger model size has historically served as a core proxy for better performance (hence the larger GPT-3 and LaMDA’s significant outperformance against their respective predecessors GPT-2 and BERT), DeepMind’s introduction of Chinchilla – a 70-billion parameter LLM – last year unveiled that parameter count is not the only key factor in optimizing performance. Specifically, Chinchilla is sized almost 3x smaller than GPT-3, 4x smaller than its predecessor Gopher (280 billion parameters), and a whopping 8x smaller than Megatron-Turing NLG, yet “uniformly and significantly” outperforms all of the above “on a large range of downstream evaluation tasks”:
As a highlight, Chinchilla reaches an average accuracy of 67.5% on the MMLU benchmark, over a 7% improvement over Gopher.
Source: deepmind.com.
The key to unlocking additional performance despite the smaller model size lies in “scaling the number of training tokens,” which refers to the number of words / text fed into training a specific LLM. Chinchilla is trained on 1.4 trillion tokens, which is more than 4x the 300 billion tokens that its predecessor Gopher was trained on, and almost double the 780 billion tokens that Google’s PaLM was trained on. The finding underscores how some of the world’s largest LLMs are essentially “oversized” or “undertrained,” and potentially “sub-optimal.”
Model Size vs. Training Tokens for Top-Performing LLMs (“A New AI Trend: Chinchilla (70B) Greatly Outperforms GPT-3 (175B) and Gopher (280B)”)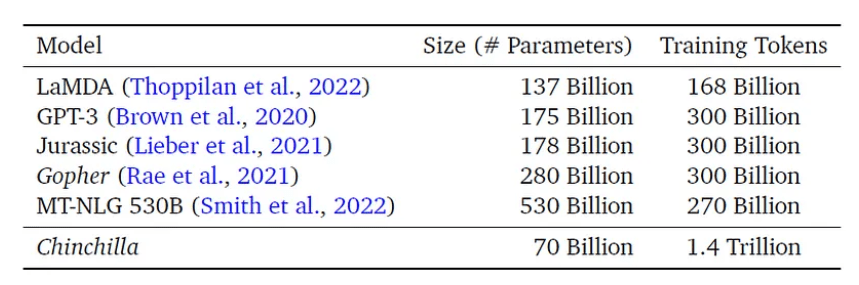
And LLaMA’s outperformance against some of the world’s largest and most powerful LLMs, despite its smaller size, is made possible by the same notion of scaling up the number of tokens in model training. The smallest LLaMA-70B is trained on 1 trillion tokens, while the larger LLaMA-33B and LLaMA-65B are trained on 1.4 trillion tokens similar to DeepMind’s Chinchilla.
Two key benefits of scaling up the number of training tokens – the core approach leveraged in developing LLaMA – are 1) higher performance – as discussed above, and 2) lower cost. Specifically, because LLaMA is significantly smaller in size, the costs of training and fine-tuning the model for specific use cases with relevant data are effective lowered, without compromising on performance improvements.
However, while a higher number of training tokens could potentially bolster performance of specific LLMs, it also introduces complexity in verifying the accuracy of input data, creating a “paradox” over the balance of performance and safety of deployment:
Emily M. Bender, a professor of linguistics at the University of Washington, criticized Google’s approach to PaLM because 780B tokens (the amount of data they used to train the model) is too much to be well documented, which makes the model “too big to deploy safely.”
Source: “A New AI Trend: Chinchilla (70B) Greatly Outperforms GPT-3 (175B) and Gopher (280B).”
This again drives home the key concerns over limitations of generative AI applications like ChatGPT, spanning information inaccuracy and bias. Related concerns had marked the demise of Meta’s “Galactica” – a LLM demo catered to scientists introduced to the public late last year that was quickly withdrawn after three days due to its overwhelming inability to “distinguish truth from falsehood.”
Implications for Meta
As mentioned in the earlier section, LLaMA is currently offered under a limited availability model focused on non-commercial licensing to LLM-research-related use cases. This would mitigate risks of the performance versus safety of public deployment paradox discussed in the earlier section, and reduce the likelihood of a similar mishap to Galactica’s failed introduction, while contributing to the elimination of LLM limitations over the longer-term:
As a foundation model, LLaMA is designed to be versatile and can be applied to many different use cases, versus a fine-tuned model that is designed for a specific task. By sharing the code for LLaMA, other researchers can more easily test new approaches to limiting or eliminating these problems in large language models. We also provide in the paper a set of evaluations on benchmarks evaluating model biases and toxicity to show the model’s limitations and to support further research in this crucial area.
Source: ai.facebook.com.
Meanwhile, down to the fundamentals, although LLaMA is currently not a direct growth driver for Meta, it potentially paves way for cost-effective LLM deployment in the future when the adoption of related applications and use cases gain momentum. Specifically, LLM application spans far beyond chatbots to a limitless range of use cases from gaming to productivity software. Growth opportunities stemming from demand for generative AI is expected to grow at a CAGR of more than 30% towards the end of the decade and potentially become a $50+ billion market. This accordingly underscores favorable prospects for Meta’s latest dip of its foot into the subfield of conversational AI in its grander scheme of plans for making AI one of its “major technological waves” alongside the build-out of the metaverse. The cost-effective aspect of LLaMA is also expected to cater favorably to Meta’s SMB-focused customer base, and allow them to access LLM-enabled use cases in the future without compromising on performance despite their potential lack of budget and resources to deploy larger-sized LLMs.
As discussed in our series of coverage on Meta, the stock remains undervalued on both a relative and absolute basis considering its profitability profile, growth prospects, and existing technological competitive advantages compared to peers. The latest introduction of LLaMA, which differentiates Meta’s position as a contributor in the ongoing development of LLMs as opposed to an immediate monetizer like its big tech peers Google and Microsoft, also reinforces confidence that the company’s technological advantage remains far from obsolete, bolstering upside potential on the horizon still from current levels.
Disclosure: I/we have no stock, option or similar derivative position in any of the companies mentioned, and no plans to initiate any such positions within the next 72 hours. I wrote this article myself, and it expresses my own opinions. I am not receiving compensation for it (other than from Seeking Alpha). I have no business relationship with any company whose stock is mentioned in this article.
Thank you for reading my analysis. If you are interested in interacting with me directly in chat, more research content and tools designed for growth investing, and joining a community of like-minded investors, please take a moment to review my Marketplace service Livy Investment Research. Our service’s key offerings include:
- A subscription to our weekly tech and market news recap
- Full access to our portfolio of research coverage and complementary editing-enabled financial models
- A compilation of growth-focused industry primers and peer comps
Feel free to check it out risk-free through the two-week free trial. I hope to see you there!